
该论文基于纯安全事件数据采用无监督的方法对安全事件做分类分级,发表于安全四大顶会S&P2022,一作Thijs van Ede是加州大学圣芭拉分校的博士生。
简介
该论文基于纯安全事件数据采用无监督的方法对安全事件做分类分级,发表于安全四大顶会S&P2022,一作Thijs van Ede是加州大学圣芭拉分校的博士生,2020年在NDSS上有一篇在加密流量上做手机app指纹识别的文章,本文合作公司为VMware,文中未公开的数据集为LASTLINE (LASTLINE 公司被VMware收购)提供,论文公开了源码,地址为:https://github.com/Thijsvanede/DeepCASE
在企业内部,安全设备每天会产生海量安全事件,运营人员需要从事件中判别能对企业造成威胁的攻击进行处置。从海量事件中找出有威胁的攻击会产生“告警疲劳”问题,使运营人员不堪重负,从而忽略部分事件,产生漏报。
而一些已有的自动化告警研判的工作需要结合终端数据来研判某个告警,不仅比较费时,在很多情况下,终端数据都无法拿到,实用性不强。本文仅利用事件数据,在研判某事件时,取该事件的周边事件进行上下文分析,判定该事件的威胁程度。并且论文提供了可解释模块,可解释为什么某事件被判定为恶意事件。DEEPCASE能够过滤86.72%的事件,减少90.53%的工作量。
主要方法
论文的核心观点是:需要对单独事件进行关联分析来进行判定。DEEPCASE的流程图如图一所示,在接收到安全设备产生的事件后,将一个事件的前序事件(context)取出,并结合该事件形成序列(sequence),利用深度学习模型将序列进行向量化,之后利用一个相似性方程对序列进行聚类,运营人员对同一类中的事件采取相同的动作即可。
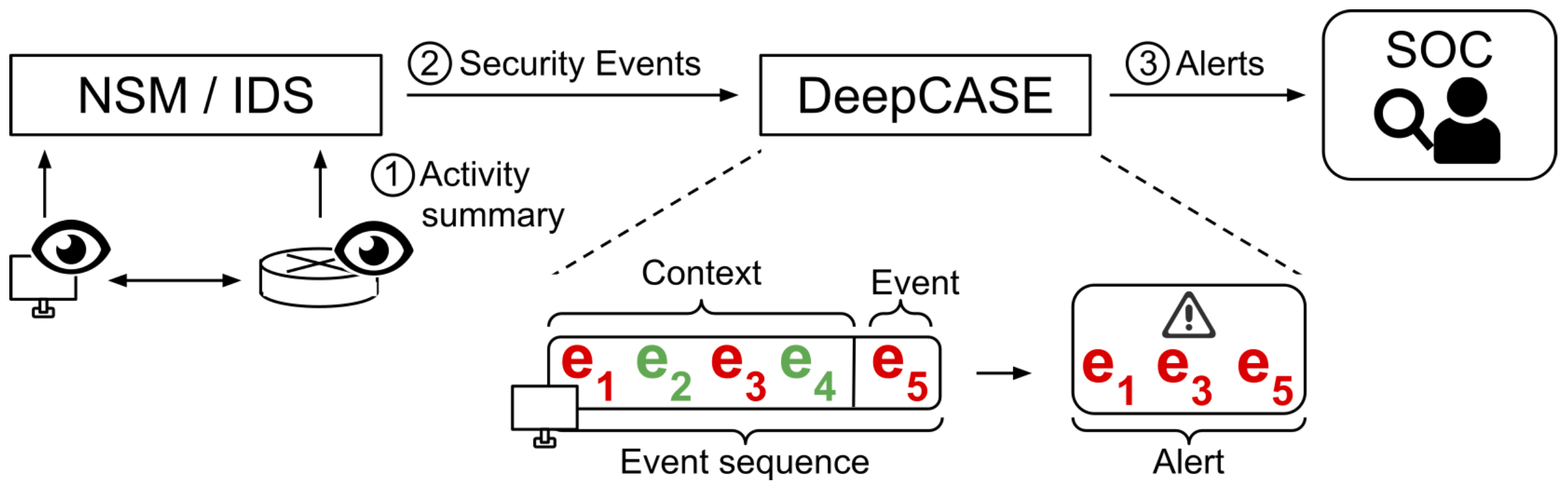
上图为DEEPACSE的详细架构图,详细流程为:
- 取每个安全设备的事件序列(sequence)作为输入
- Context Builder识别与当前事件($e_5$)相关联的事件(contextual event ,虚线方框$e_1, e_3$)、对每个序列进行向量化(attention vector ),利用这些向量计算序列的相关性
- Interpreter 对这些序列进行聚类
- 运营人员对所得聚类打标签,而不是传统的对单个事件打标签
- 一旦运营人员对类打过标签,相似序列(基于contextual event 和 attention vector 共同判断)便可被自动分类。

上图中:
Sequencing events:对于每个事件,取其前n个事件(论文中取10)作为上下文形成序列,并且序列之间的时间间隔不大于1天。(个人感觉应该是基于单个主机的前n个事件)
Context Builder:目标是发现相关事件(发现攻击事件,去除正常事件)并且向量化。在这里,本文用attention 机制来发现相关事件。如图3所示,先将序列进行编码(Encoder),生成context vector c0,c0结合上一次的预测结果ei-1生成attention vertor,经过解码,若能预测出当前事件ei,则认为前序事件与当前事件有相关性。 总之Context Builder可以计算当前事件与前序事件的相关性,并给出比重,依据比重对前序事件进行向量化
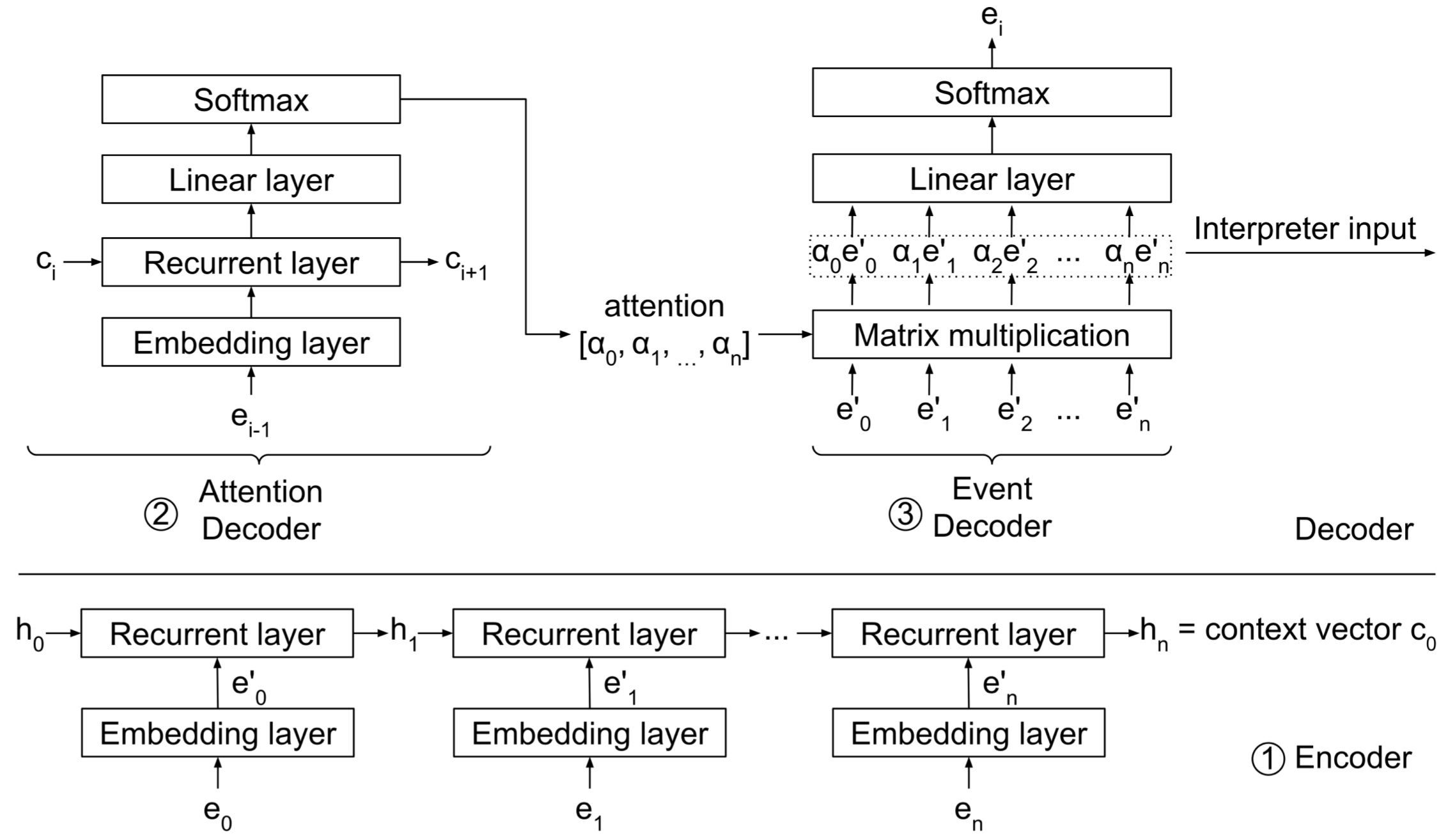
- Interpreter:该模块根据上一步序列的向量化结果,对同类别事件的不同前序事件序列进行聚类。Interpreter通过计算向量的$L_1$距离来衡量向量之间的远近,用DBSCAN算法进行聚类
- Manual analysis:在该阶段,需要对每个类人工打标签,判断该类是良性的还是恶意的
- Semi-automatic analysis: 若新的事件序列落在已知类里,则直接可分类,若没有在任何一个已知类里,则进行人工研判
数据集
文中用了两个数据集,一个是公开数据集,另一个不公开。公开数据集用于复现论文中的方法,非公开数据用于验证实际效果。
- LASTLINE 数据集:该数据集包含395个检测器,共检测38.8万台设备,事件数量为1050万条,事件类型共计291种,时间跨度为5个月,包含20个组织的数据。其中270万条事件可能为攻击数据,当中4.5万条已经被确定是攻击(恶意软件产生),4.6万条被分类为高风险事件(如,知名漏洞利用),18.5万条为中风险事件(如,不知名漏洞利用),270万条为低风险事件(如,使用BitTorrent),剩余的事件为780万条,与安全事件无关
- HDFS 数据集:该数据集是DeepLog论文中使用的数据集,由亚马逊云机器的系统日志组成,其中2.9%的事件被标记为异常,该数据集用于评估DEEPCASE方法对于工作量的减少程度,以及便于论文复现
实验结果
在LASTLINE数据集上,DEEPCASE最终将94.46%的事件聚类到1642个类中,剩余5.54%的事件(11万条)无法聚类,需要人工研判;原始事件有5种(INFO,LOW,MEDIUM,HIGH,ATTACK),聚出的类分为6种,多了SUSPICIOUS 类,若同一个类中的事件包含多个种类,则将类当成SUSPICIOUS 类,共计238 个。
本论文的实验做得比较仔细,大致分为3个部分:工作量减少量实验、准确率实验、事件预测效果实验。(值得学习,想方设法论述自己方法的优点)
工作量减少实验
首先是工作量减少量实验(图4),在方法列中:Cluster N-gram是指把N个事件当成一个类,Cluster DEEPCASE指不用Context Builder进行聚类(用以说明Context Builder的必要性),Alert throttling指一段时间内,若同一个事件出现多次,则当成一条告警处理,这种方式下,时间越长,需要研判的告警就越少,Rules指利用专家规则,将多个事件组合成一条告警,其中AlienVault 和Sigma 的规则库都是公开的;其他列的含义如下:
- Alert: 最终需要运维人员研判的告警
- Reduction:计算告警和覆盖事件(94.46%的能聚类的事件)的比值
- Coverage:能聚类的事件覆盖率
- Overall: 运营人员需要研判的告警 + 未能聚类的事件 / 总事件

准确率实验
该实验比较一个事件序列的真实标签和预测标签,若预测标签的风险等级低于实际标签,则认为有可能会遗漏攻击,实验结果表明,只有47个序列的风险等级被低估,占比不到0.001%

事件预测实验
DEEPCASE用类似于Auto-Encoder的方式利用前序事件预测当前事件,文章将该事件预测方法与之前的文章做了对比,实验表明,在事件预测的效果上DEEPCASE也是占优。

个人总结
DEEPCASE是第一篇仅根据网络侧数据本身对事件做分类的文章,与我们的研究内容完全契合,可深度借鉴。
借鉴点
- 聚类方法。我个人认为告警不应该单条处置,而是批量处置,应该聚类,该论文提供了一种聚类思路
- 上下文分析的方法
优缺点分析
优点
把单条告警的研判转化成批量研判,提升运营效率。
缺点或不足
- 可以批量研判的前提是同一类中的事件实际上也属于同一分类。但是不能保证同一类中,序列是同一分类,同一序列中,事件是同一分类。文中论述不够详细
- 数据集问题。ATTACK攻击类型都是恶意软件触发的,是最高危的类型,但个人的渗透攻击、甚至某些APT攻击并没有在数据集,这些攻击触发的事件较少,不一定能被DEEPCASE处理,缺少该部分论述,准确性存疑
- 事件误报问题。观察到告警类型中有“beacon activity”,这种检测不一定准,那么可能也有其他事件类型不准的情况,这种不准的情况下,预测该事件就丧失了意义,缺乏该部分的讨论
待改进之处
- 需要考虑事件自身特性!仅根据事件的前序对事件进行判别,显得不合理。就跟只根据别人的评价来判断一个人一样,显得有些舍本求末了
- 可以加入后续序列,像word2vec一样,双向预测。对攻击来说,当前的攻击行为,不仅跟前序有关系,跟后序也是有关系的,可提升准确率
- 必须考虑事件误报问题
引用
[1] van Ede, Thijs, et al. "DEEPCASE: Semi-Supervised Contextual Analysis of Security Events."2022 Proceedings of the IEEE Symposium on Security and Privacy (S&P). IEEE. 2022.
[2] Github 源代码:https://github.com/Thijsvanede/DeepCASE

更多推荐