
OpenAI 9月21号开源了一个新的自动语音识别(Automatic Speech Recognition, ASR)模型Whisper。Whisper模型的训练使用了680k小时的多种语言的语音数据(从网络上搜集而来)进行训练。此模型在不同的口音、背景噪声以及专业术语等上下文环境下都相当鲁棒。此外该模型还支持其它语言(共99种)的语音识别,并支持自动翻译为英文。
背景
近些年,无监督预训练技术在海量数据的支撑下发展迅速,语音识别技术也在此过程中得到了长足发展。预训练的语音编码器可以为语音数据输出高质量的特征表示,以用于下游任务。由于预训练模型仅能为输入数据输出信息丰富的中间特征表示,为了能用于下游任务,预训练模型还需要配合解码器来使用,也就是在下游数据上微调。
预训练+微调方案的一个问题是:下游任务的数据量通常与预训练模型的数据量不在一个量级(下游任务的数据通常不是特别多)。数据量较少通常就会带来范化性差、域漂移等问题。在一类数据上表现好的模型可能在另外的数据上的表现就会较差,鲁棒性较差。如果想要获得大量的高质量的下游任务的数据,就会消耗大量的人工成本。在此背景下,Whisper被提出。
弱监督(Weak Supervision)是机器学习的一类方法。此类方法所用数据集的标签中通常都包含了大量的噪声,或者标签本身并不准确。它的好处是通常无需耗费太多昂贵的人工成本即可获取海量的数据集。
Whisper旨在说明海量数据(相对于现有的监督数据集的量)对监督预训练模型的性能影响是非常大的。 Whisper是一种弱监督学习方法,它可以利用网络上大量的公开数据作为训练素材。最终,Whisper的训练数据包含了680,000小时的语音数据,这个数据量相比于当前语音监督学习的数据集高了一个数量级。最终的Whisper模型展现出了非常好的性能表现以及鲁棒性。
Whisper
数据处理
数据清洗
本文所使用的数据集从网络上搜集而来,这些数据由音频数据及其对应的文本数据组成。由于网络上的数据质量参差不齐,因此需要对其进行预处理,文中对数据进行了5种方法的处理。
- 机器自动识别数据过滤:现在网络上很多语音对应的文本数据都是通过ASR系统自动识别出来的。现有的一些研究表明,使用ASR系统自动识别出来的文本数据进行训练会极大损害模型的性能。一般,机器自动识别的文本数据通常具有某些特征,利用这些特征,我们可以对数据进行过滤
- 语言匹配:使用现有的语音语言检测模型检测语音中使用的语言,使用现有的文本语言检测模型检测文本中使用的语言。如果语音与文本中检测出的语言不匹配,那么这些数据则会被过滤掉
- 数据分段:语音文件被分为30秒的数据段(匹配了对应时间段的文本数据)。这些数据中保留了不包含语音的片段,以用于音频活动检测(voice activity detection)
- 使用初始训练模型过滤低质量数据:使用数据进行模型的初始训练,统计模型在现有数据上的错误率,使用这个错误率指导过滤低质量数据。此步骤可以过滤掉大量的语音/文本匹配较差的数据
- 重复数据过滤:从训练集中过滤掉与测试集中包含相同文本的数据
预处理
- 音频数据被全部重新采样到16k Hz
- 每25毫秒音频数据使用80通道的Mel频谱对数特征,每次步进10毫秒(width: 25ms, stride: 10ms)
- 在整个预训练数据集上对处理后的数据进行缩放,缩放到$[-1, 1]$之间,均值近似为0
输出标签
使用字节级BPE tokenizer对文字进行编码作为输出标签。对于训练全英文的模型,使用与GPT-2一样的tokenizer。对于多语言版本的模型,会重新构建词汇表,但是词汇表的总大小保持不变。
模型设计
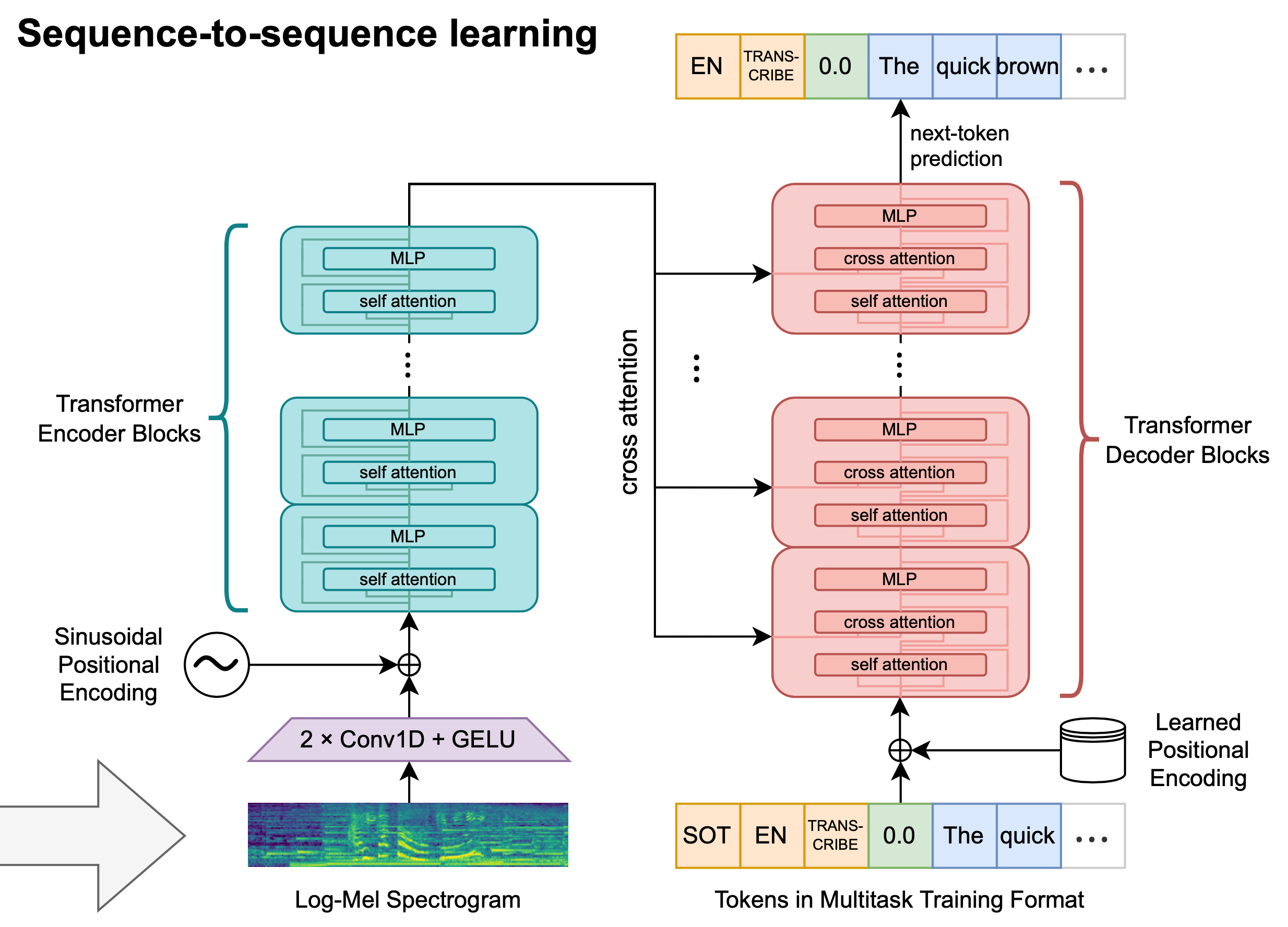
Whisper 的模型结构示意图如上图所示。Whisper 的重点是在探索海量监督数据集对模型性能的影响,而不是在模型结构本身上。所以Whisper的训练采用了标准的encoder-decoder结构的Transformer进行训练。在数据的输入端添加了一个两层的一维卷积神经网络+GELU激活函数来对输入进行处理,处理后与正弦位置编码进行相加后输入到Transformers编码器中。
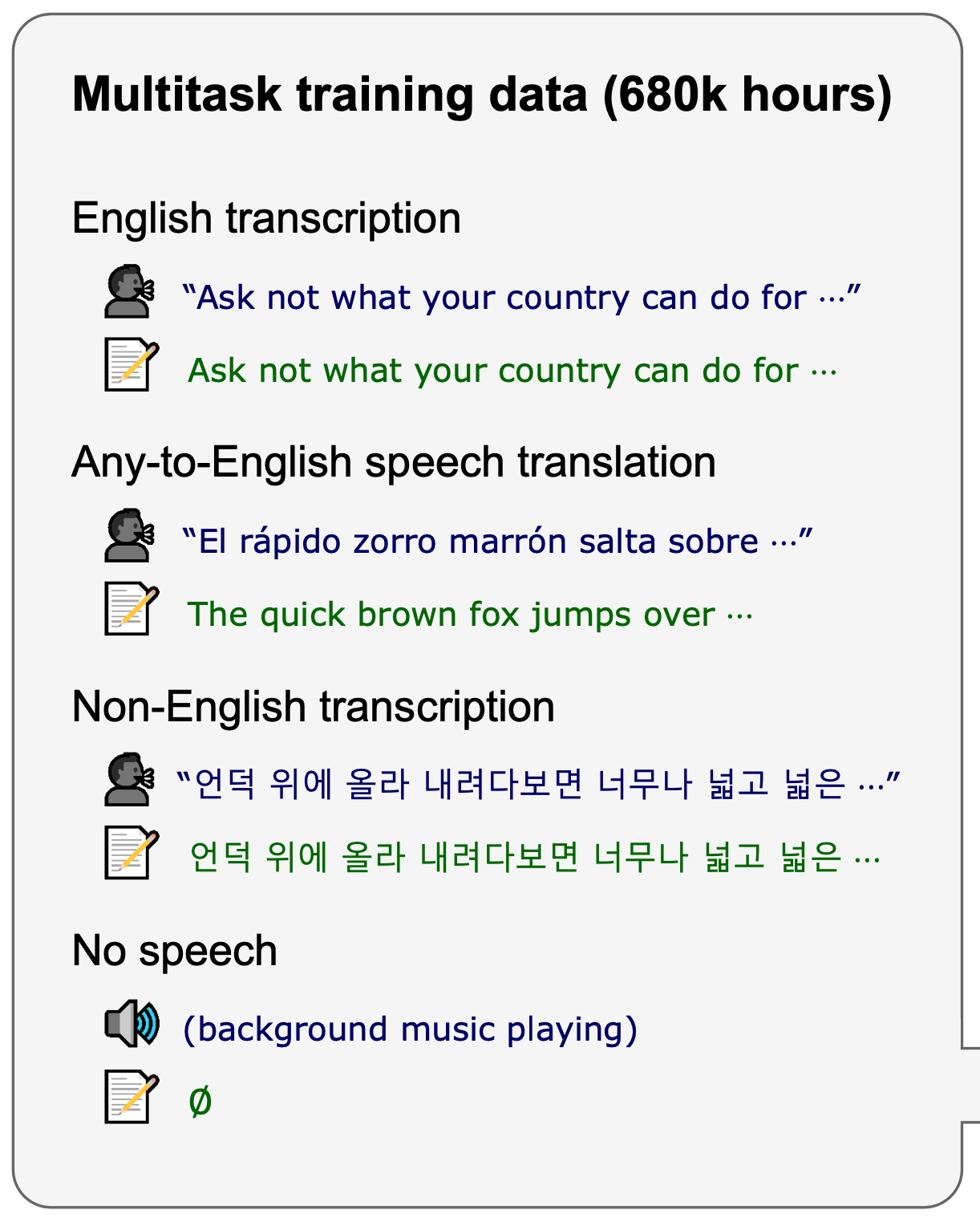
多任务训练
在语音识别有着各种各样的任务,比如最常见的话语识别、说话人区分等等。Whisper 模型的训练会同时兼顾这些任务。为了达到可以同时训练多个模型的目标,Whisper为解码器设计了一个特定格式的输入(以及对应的输出)。如下图所示,Whisper 一共混合了4个任务的训练:
解码器输入的格式如下图:
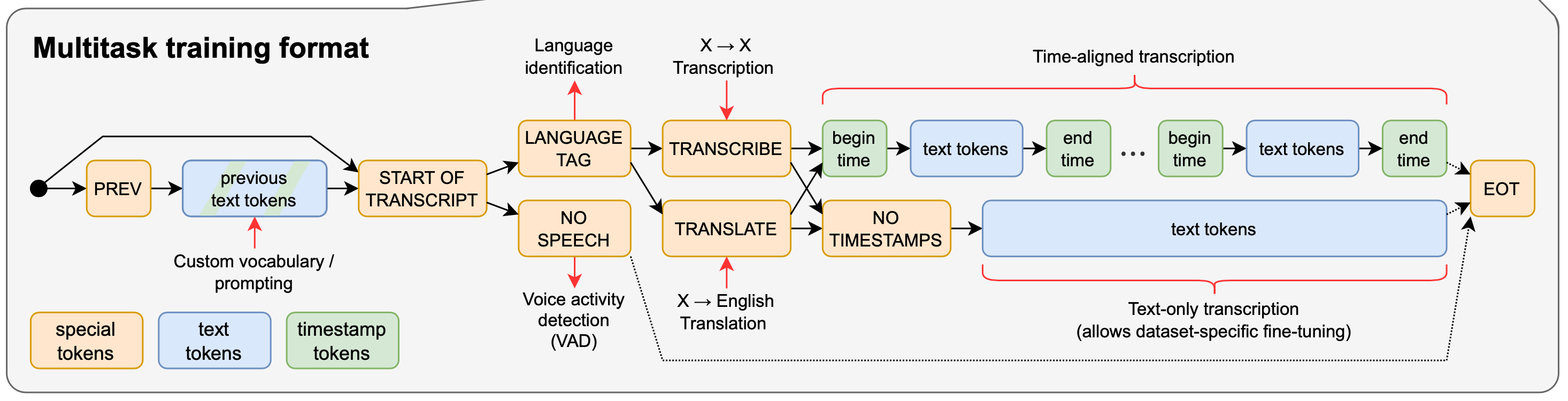
可以从以下几点看这个格式:
[PREV]|[tokens]这部分是可以省略的:这部分存在的目的主要是想让解码器可以了解到上文的背景信息以便可以对下文语音做出更加准确的预测[START OF TRANSCRIPT]或者[SOT]这个特殊的token用于指示预测任务即将开始- 解码器接收到
...|[SOT]之后会给出第一个预测:如果音频片段中包含语音数据,那么下一个输出的token用于指示语音片段中所使用的语言(语音数据中共包含了99种语言);如果音频片段中不包含语音数据,那么模型需要输出[NO SPEECH]这个特殊 token - 如果音频中包含语音,那么现有输入序列后会接上一个用于指示任务类型的token(听写/翻译)
- 如果数据集的标签数据中包含准确的字/词等所在的时间戳,那么可以让模型输出token的时间戳。所有用到的时间戳(相对于当前音频的时间偏移量)都被添加到词汇表中
- 如果不需要让模型输出时间戳,那么需要在任务类型token后面添加一个指示 token
[NO TIMESTAMPS]。在此情况下,解码器直接输出表示词汇(或片段)的token即可
其它
研究者共训练了5个不同大小的模型,参数如下:
| 模型 | 层数 | 宽度 | 头数量 | 参数量(百万) |
|---|---|---|---|---|
| Tiny | 4 | 384 | 6 | 39 |
| Base | 6 | 512 | 8 | 74 |
| Small | 12 | 768 | 12 | 244 |
| Medium | 24 | 1024 | 16 | 769 |
| Large | 32 | 1280 | 20 | 1550 |
实验结果
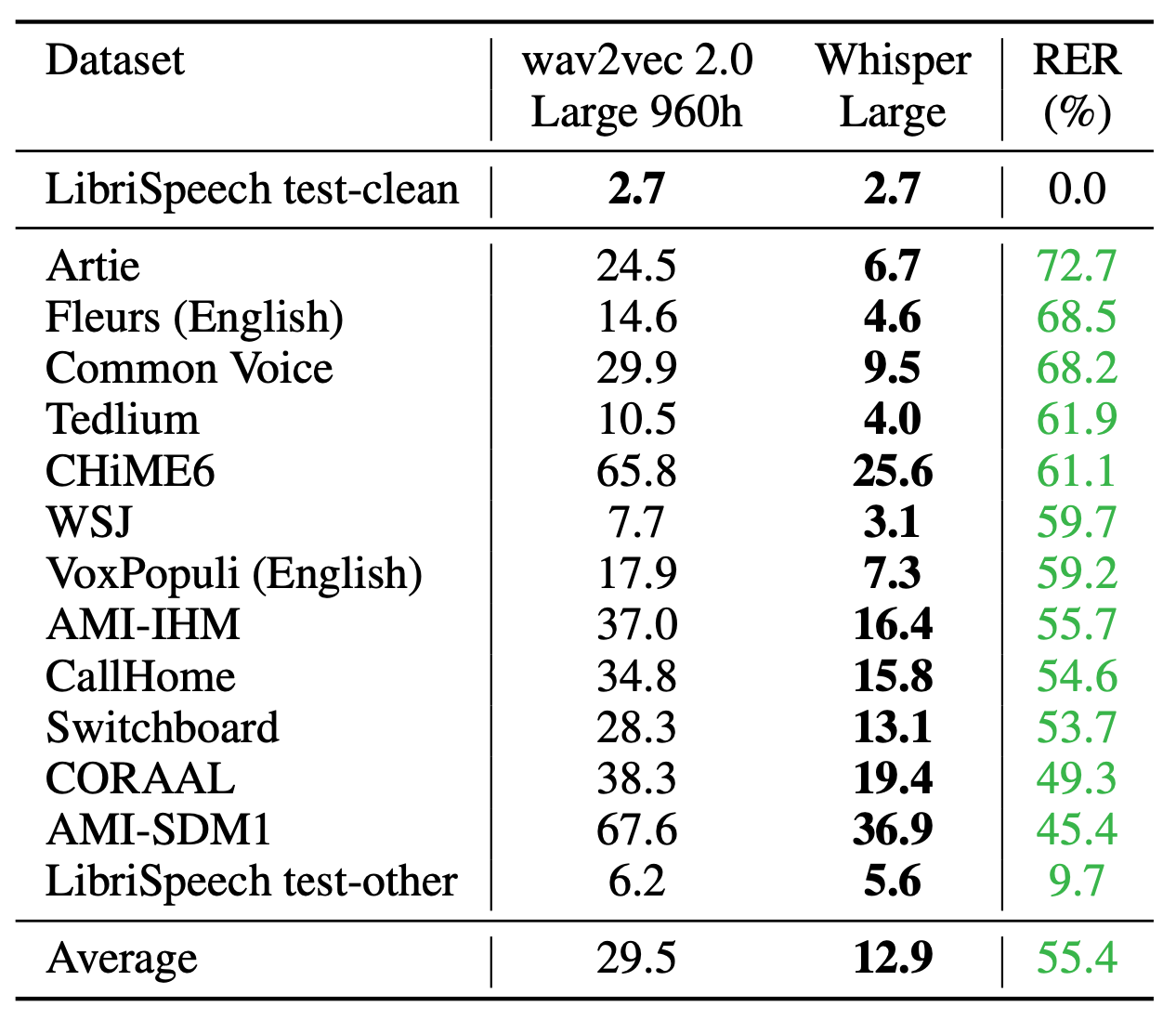
Whisper 与之前的模型相比展现出了亮眼的表现以及鲁棒性,具体效果参见论文,这里贴一个与wav2vec 2.0 对比的图表:
参考文献
[1] Radford, Alec, et al.Robust Speech Recognition via Large-Scale Weak Supervision. Technical report, OpenAI, 2022. URLhttps://cdn.openai.com/papers/whisper.pdf, 2022.
[2] 代码及数据:https://github.com/openai/whisper

更多推荐