
据图片来生成文本的任务(比如图片描述/视觉问答等)已经被研究了好些年。传统解决这类问题的系统通常会将一个对象检测网络用作一个视觉特征编码器,而后再利用一个解码器将特征向量解码为文字。由于当前此类研究数量太大,在这里我仅关注这其中的一类解决视觉语言任务的方法。
文章目录
文章翻译自:https://lilianweng.github.io/posts/2022-06-09-vlm/
根据图片来生成文本的任务(比如图片描述/视觉问答等)已经被研究了好些年。传统解决这类问题的系统通常会将一个对象检测网络用作一个视觉特征编码器,而后再利用一个解码器将特征向量解码为文字。由于当前此类研究数量太大,在这里我仅关注这其中的一类解决视觉语言任务的方法。这类方法基于预训练语言模型,可以处理视觉信号,可以看作是《通用语言模型》一文的扩展。
我粗略地将视觉语言模型(visual language models, VLMs)分为四大类:
- 将图片转化为特征嵌入向量,这些特征向量可以与token的嵌入向量进行联合训练
- 学习一个好的图片嵌入表示(image embeddings),这些图片的嵌入表示可以作为预训练语言模型的一个前缀
- 使用一个特别设计的交叉注意力机制来将视觉信息混合到语言模型中去
- 直接将视觉模型与语言模型组合起来使用(不用进行任何二次训练)
使用图片和文本进行联合训练
将视觉信息混合进语言模型的一种比较直接的方法就是:将图片看作一般的文本tokens,并且使用文本和图片两种信息的嵌入表征来联合训练模型。更准确地来说,图片被分成多个小的片段(patches),并将每个片段作为输入序列中的一个token。
VisualBert(Li 等人, 2019)将文本和图片区域(image regions)一起喂给BERT,这样模型就可以使用注意力机制来对齐文本与图片信息。
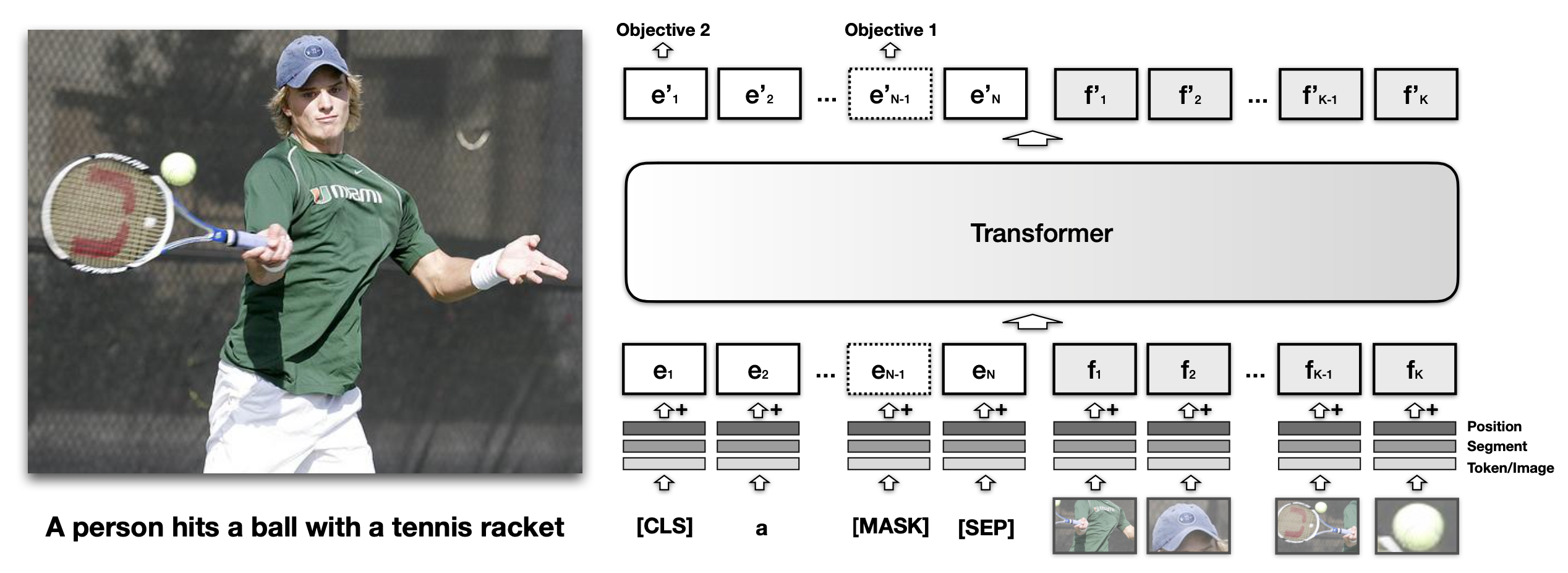
和BERT 中的文本嵌入一样,每个VisualBERT中的视觉嵌入表征也同时混合了三种类型的嵌入:
- token的特征嵌入$f_o$:使用卷积神经网络提取的图片中某个区域的视觉特征向量
- 类别嵌入(segmentation embedding)$f_s$:指示嵌入表示是否是用于表示视觉特征而非文本特征
- 位置嵌入(position embedding)$f_p$:用于指示图片中对应的区域位置
模型使用了MS COCO 数据集来训练,此数据集包含了很多图片及其对应的标题。模型使用了两个目标:
- 带图片的MLM:模型需要来预测被屏蔽的文本(masked text tokens),此时图片嵌入表示一直保持非屏蔽状态
- 句子-图片预测:模型使用一张图片与两个图片的标题作为输入,两个标题中的其中一个以50%的概率随机选择任意一个标题,模型被用于区分这两种情况
对比实验结果表明将视觉信息早点混合进transformer中来训练模型是非常重要的。使用预训练的BERT模型来初始化以及句子-图片预测训练目标这两点的影响相对较小。

VisualBERT 在NLVR和Flickr30K上的性能超过了当时的SoTA方案,但是在VQA上仍然与当时的最好方案存在差距。
SimVLM(Simple Visual Language Model;Wang 等, 2022)是一个简单的前缀语言模型,其中前缀序列通过类似BERT的双向注意力机制来处理,但是主输入序列与GPT一样仅用因果注意力机制(causal attention)。图片被编码为前缀tokens,这样模型可以完全吸收视觉信息,而后使用自回归的方式来生成相关文本。
受到ViT与CoAtNet的启发,SimVLM 将图片分割为许多小区域(smaller patches)的一维序列。他们使用ResNet的前三个卷积块来提取图片区域的上下文信息,此种方式相比直接使用线性映射性能更佳。
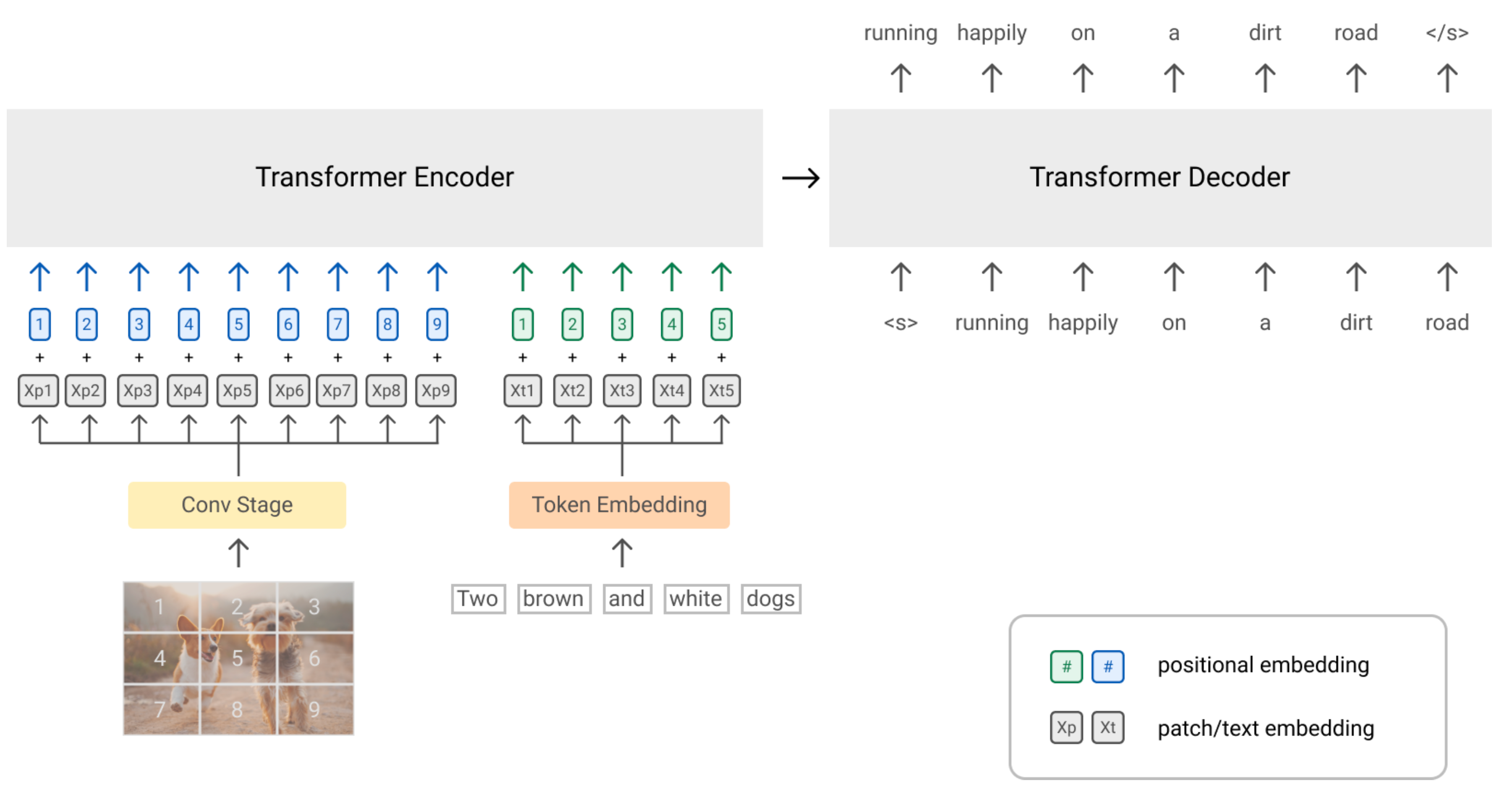
SimVLM的训练数据包含了大量的图片-文本数据对(来自ALIGN)以及纯文本数据(来自C4)。作者们将两种预训练数据混合在一起进行训练,每个batch数据包含了4096个图片-文本数据对以及512个纯文本文档。
对比实验发现:使用图片-文本对数据以及纯文本数据同时进行训练是非常重要的。PrefixLM目标的性能表现同时超过了span corruption与朴素的LM。
CM3(Causally-Masked Multimodal Modeling;Aghajanyan 等人,2022)是一个超文本语言模型,它用于学习生成大量与CC-NEWS 与 维基百科文章的HTML网页类似的web内容(包含超文本标记、超链接以及图片)。最终的CM3模型可以在任意文档标记的上下文中生成丰富的结构以及多模态内容。
从整体架构来说,CM3是一个自回归模型。但是为了将因果(casual)与MLM组合起来,CM3在训练时还会屏蔽掉(masked)少量的tokens长串,这些被屏蔽的长串模型会在序列末尾重新被生成出来。
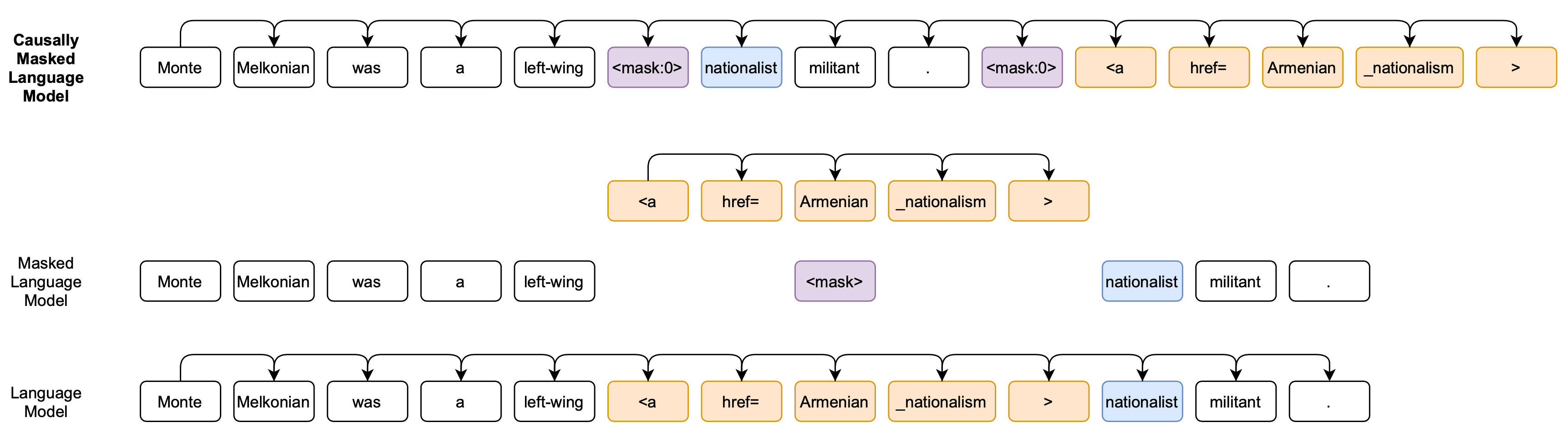
CM3的训练集包含了大约1T的Web数据。在预处理阶段,src字段对应的图片被下载下来,而后被重新裁剪成256x256的大小。这些裁剪后的图片使用VQVAE-GAN来处理,从而被转变为tokens。之后,这些tokens又被使用空格连接在一起,被重新插入到对应src属性的位置。
基于提示(prompt)的方法,CM3可以被用于完成几类任务:
- 图片恢复(in-filling),提示结构为:
Infilling Prompt: <img src="{prefix}<mask:0>{postfix}"><mask:0>- 带条件图片恢复,提示结构为
Conditional Infilling Prompt:
<img alt="Photo: {text}" src="{prefix}<mask:0>{postfix}"><mask:0>- 带条件的图片生成,提示结构为:
Conditional Generation Prompt: <img alt="{prompt}"- 图片标题生成,提示结构为:
Captioning Masked Prompt #1:
<img alt="Photo: A photo taken of<mask:0>" src="{image}">
Captioning Causal Prompt #1:
<img src="{image}" title="Photo: A photo taken of- 实体歧义消解:
Original: Manetho writes that these kings ruled from
<a title="Memphis, Egypt">Memphis</a>
Prompt: Manetho writes that these kings ruled from <a title="<mask:0>">Memphis</a>...<mask:0>
Target: Manetho writes that these kings ruled from <a title="<mask:0>">Memphis</a>...<mask:0> Memphis, Egypt将图片嵌入作为语言模型的前缀
如果我们希望在不改变语言模型参数的前提下,将其适配以用于处理视觉信号,那么我们应该怎么办呢?在此种情况下,我们需要为图片信息找到一个与语言模型的嵌入空间想对应的一个空间。
受到前缀或者提示微调方法的启发,Frozen(Tsimpoukelli 等,2022)与ClipCap(Mokady, Hertz & Hertz, 2021)这两种方法在训练阶段都只更新视觉模块的参数。视觉模块用于生成一个可以直接用于预训练语言模型(固定不变的)的图片嵌入表示。这两种方法都用了图片-标题对齐数据集进行训练,他们使用图片以及已知的前缀文本来预测下一个词。通过此种方式,语言模型的强大能力就可以被直接利用。虽然在此种设定中,模型仅使用了有限的图片-标题数据来进行训练,在测试阶段它仍然可以使用强大的语言模型。
Frozen利用NF-Resnet的全局池化层的输出作为视觉编码,它可以被当作一个多模态的 few-shot学习器来使用。在测试阶段,可以通过交替插入图片及文本序列的方式,将其适配到新的zero-shot或者few-shot任务中。
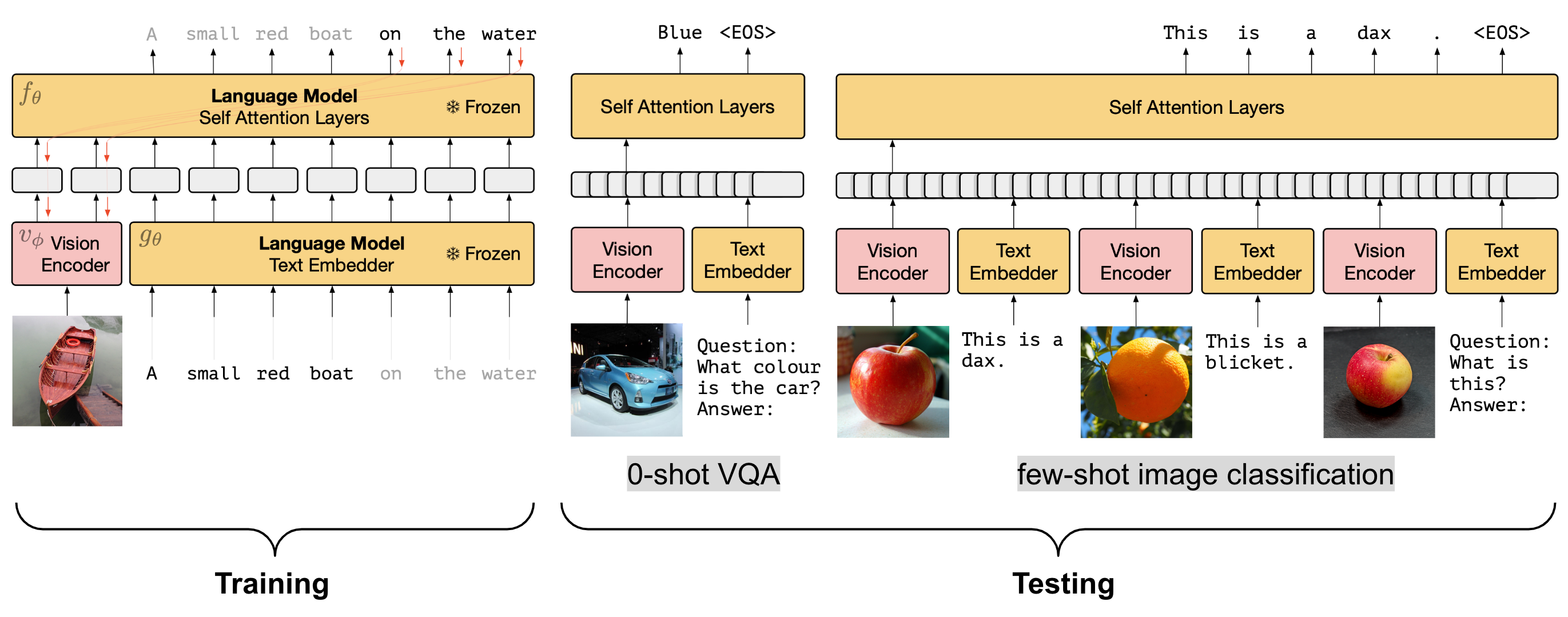
Frozen最终的实验结果很有意思:在预训练语言模型上进行微调之后会导致它在VQA任务上的性能变差。此外,使用预训练的版本来初始化语言模型而非从零开始训练一个语言模型$(Frozen_{scratch})$非常重要(重新训练看起来没软用)。用作对比的基线模型为$Frozen_{train-blind}$,在此基线版中,图片会被完全涂黑。虽然图片信息被完全屏蔽,但是从最终结果来看,它仍然可以取得像样的性能(预训练语言模型的魔力)。

ClipCap 依赖于CLIP(Radford 等人, 2021)进行编码,它依赖于一个轻量级的映射网络$F$来将图片嵌入向量空间对齐到预训练语言模型的语义空间中去。网络$F$将CLIP输出的嵌入向量映射为$k$个嵌入向量的序列,每个向量的维度与GPT2的词向量维度一样。增加前缀序列的长度$k$可以提升性能。CLIP的视觉编码器与语言模型在训练期间都固定不变,训练期间仅训练映射网络$F$。实验发现语言模型固定时,$F$需要使用一个transformer(8层多头自注意力层,每层8个头);如果语言模型可以被微调,$F$仅需使用一个MLP即可。
虽然ClipCap仅训练了很少的参数,它仍然可以在图片描述(加标题)任务中获取不错的性能,可以与当时的SoTA比肩(如:Oscar,VLPL,BUTD)。因此,作者猜测:
“CLIP空间中已经囊括了所需信息,将这些信息转化为一个特殊的风格并不会提高它的灵活性。”
“the CLIP space already encapsulates the required information, and adapting it towards specific styles does not contribute to flexibility.”
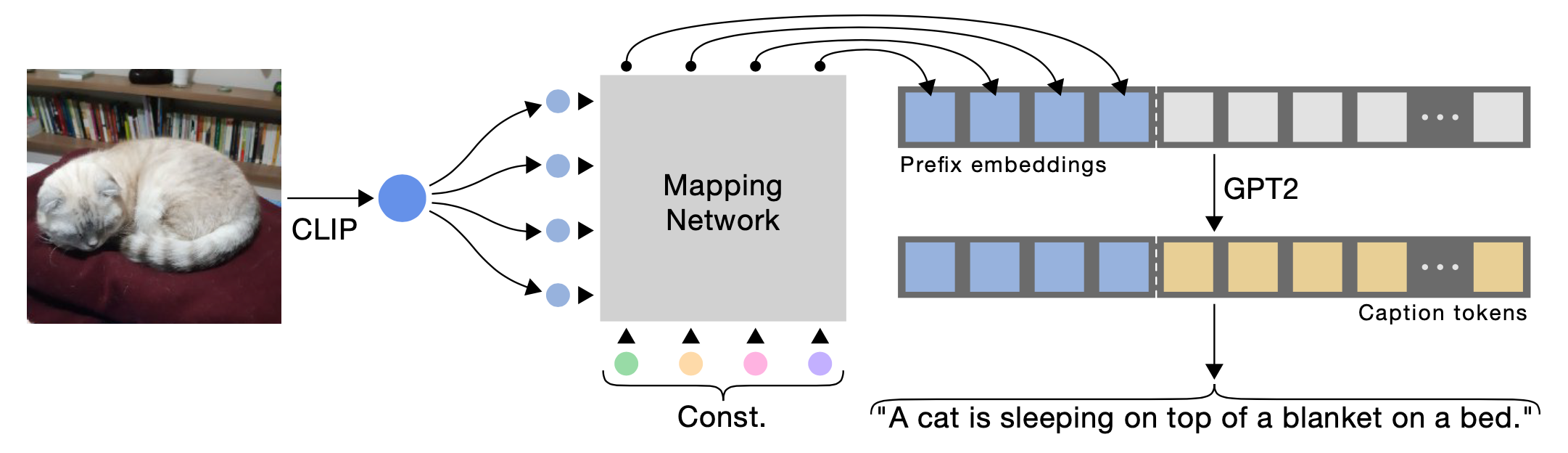
一个有趣的事实是:由于ClipCap将图片嵌入翻译到了语言模型空间中,处理过的前缀甚至可以被解释为单词。

文本-图片交叉注意力混合机制
为了在语言模型的不同层中更有效的利用视觉信息,我们可以考虑使用一种特别设计的交叉注意力混合机制来平衡文本生成信息与视觉信息。
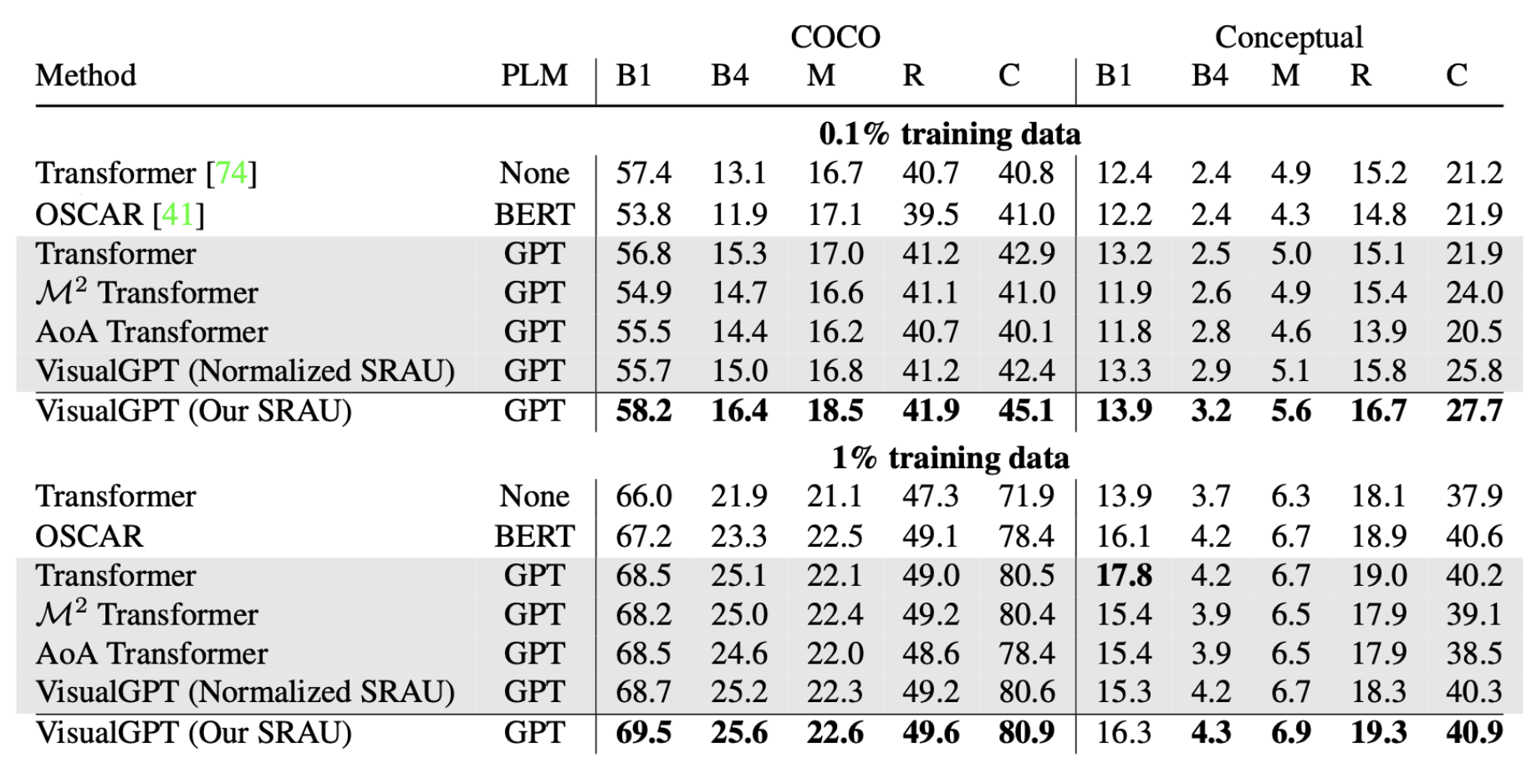
VisualGPT(Chen 等人, 2021)中引入了一种自活(self-resurrecting)编解码器,编解码器基于注意力机制设计。这种结构可以帮助预训练语言模型仅需通过少量的域内(in-domain)图片-文本数据即可进行快速适配。
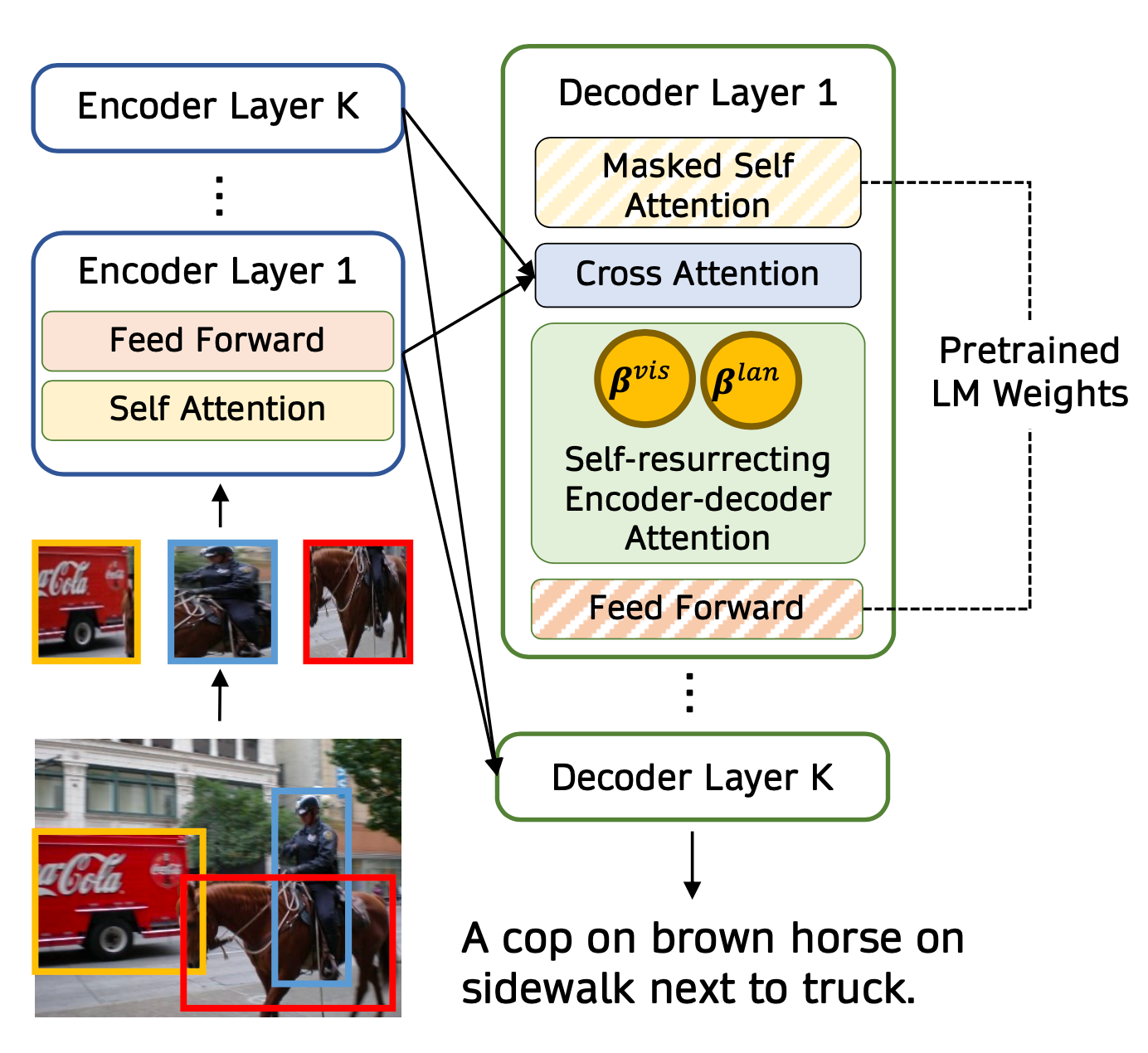
令$I$为视觉编码器的输出,$H$为语言模型解码器的隐层状态。VisualGPT中引入了一个自激活单元(self-resurrecting activation unit, SRAU)来控制语言信息$H$与视觉部分$EncDecAttn(H, I)$的平衡。SRAU 中使用了两个门$B^{vis}$和$B^{lan}$来分别控制视觉部分与语言部分:
$$
\begin{aligned}
& B^\text{vis} \otimes \text{EncDecAttn}(H, I) + B^\text{lan} \otimes H \\
\text{其中 }
& B^\text{vis}[i,j] = \sigma(H[i,j]) \mathbb{1}[\sigma(H[i,j])\tau] \\
& B^\text{lan}[i,j] = (1 - \sigma(H[i,j])) \mathbb{1}[1 - \sigma(H[i,j])\tau] \\
\end{aligned}
$$
其中$\otimes$表示按元素相乘,$[i, j]$表示取矩阵中某一元素。$\tau$是一个预定义的阈值参数。
VC-GPT(Visual Conditioned GPT;Luo 等人, 2022)将视觉预训练模型与语言预训练模型组合起来,其中视觉编码器使用一个预训练的视觉transformer(CLIP-ViT),语言编码器使用一个预训练的语言模型。
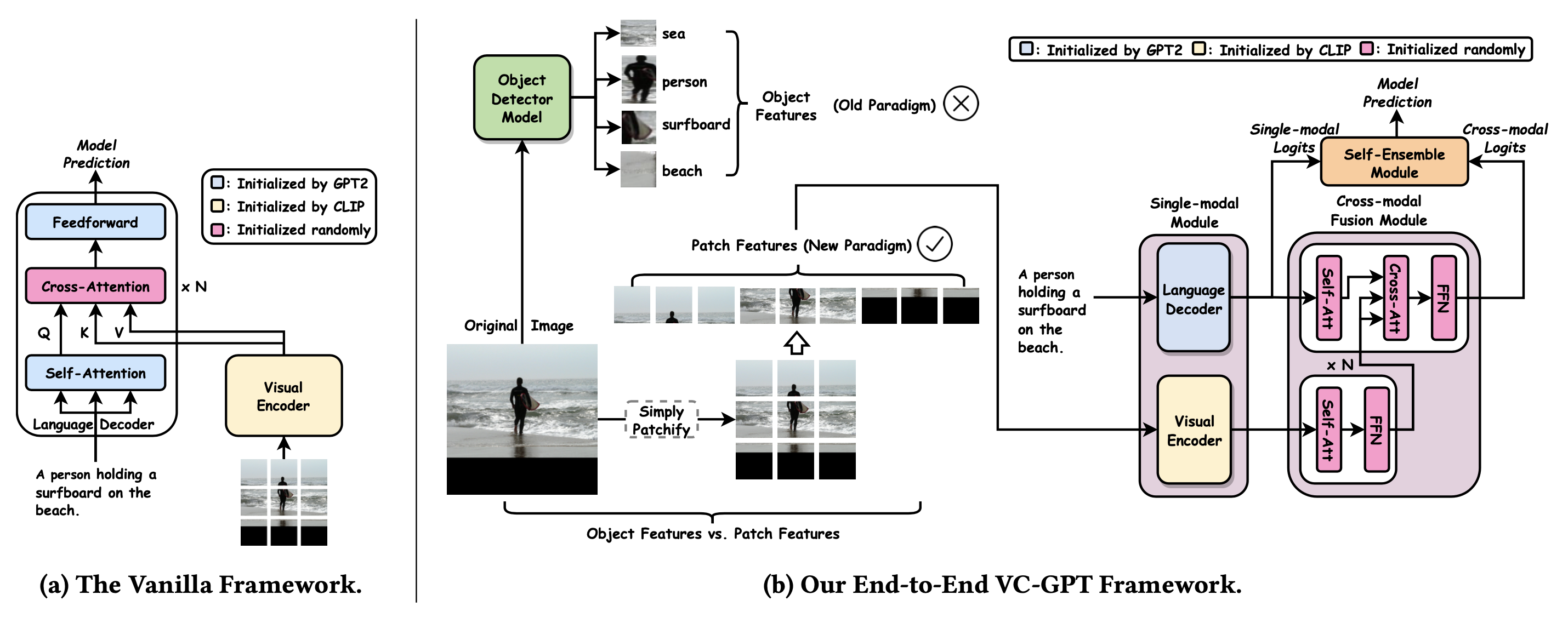
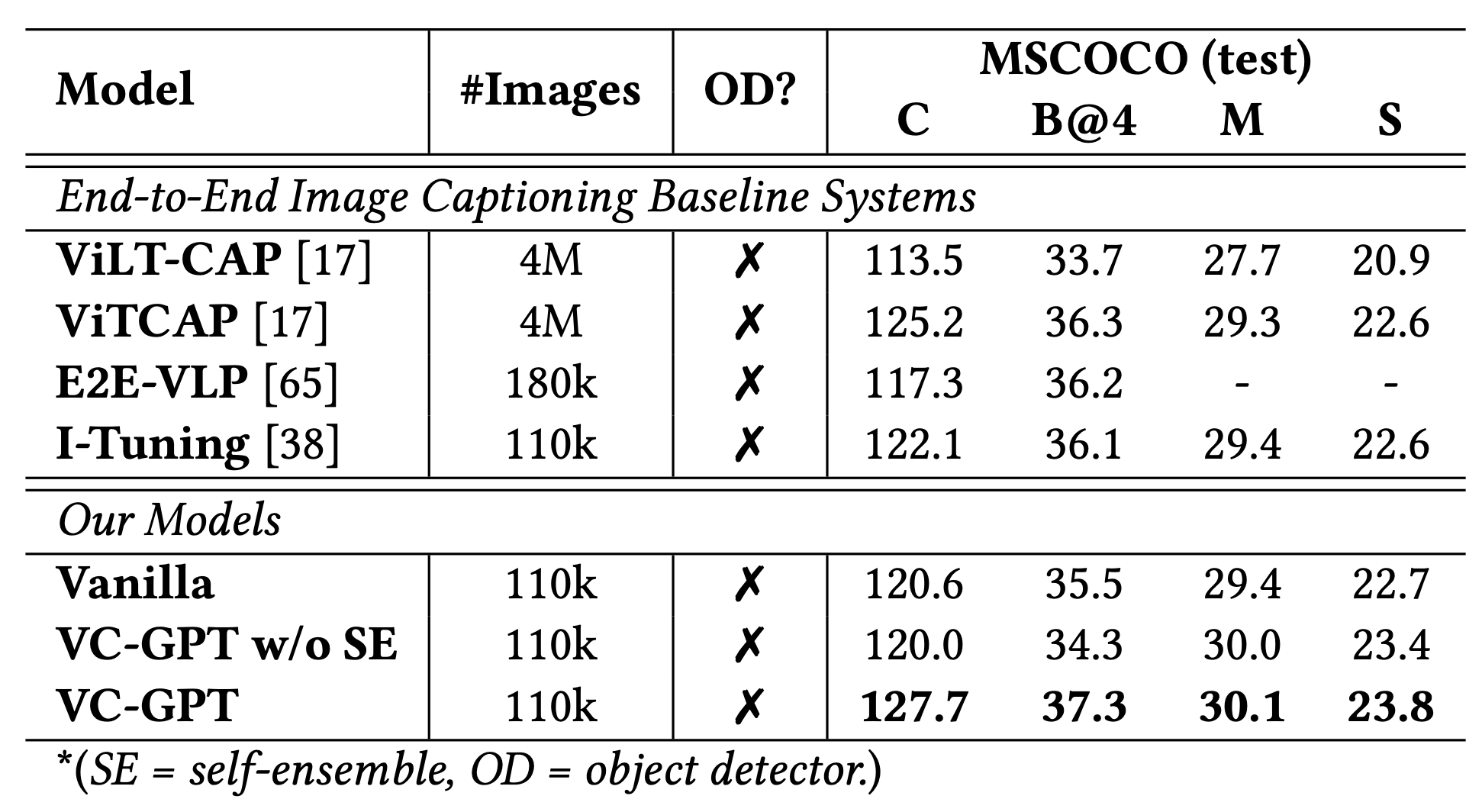
CLIP-ViT 将图片分割为多片的序列作为输入,而后为每个分片输出一个向量表示。为了避免灾难性遗忘(catastrophic forgetting),视觉信息没有被直接注入到GPT2中,VC-GPT在视觉编码器后以及语言编码器后加了一个额外的交叉注意力机制层。而后,自聚合(self-ensemble)模块将单模型语言解码器输出的logits$h^G$与交叉模型的视觉-语言混合模块输出的logits$h^{fuse}$线性组合起来。该自聚合模块对于性能提升来说非常重要(见"VC-GPT w/o SE" 图13)。
$$
\text{logits} = W^G h^G + W^\text{fuse}h^\text{fuse}
$$
其中$W^G$为语言解码器的线性映射,它通过GPT2的词嵌入向量来初始化。$W^{fuse}$是混合模块的线性映射,它是随机初始化的。
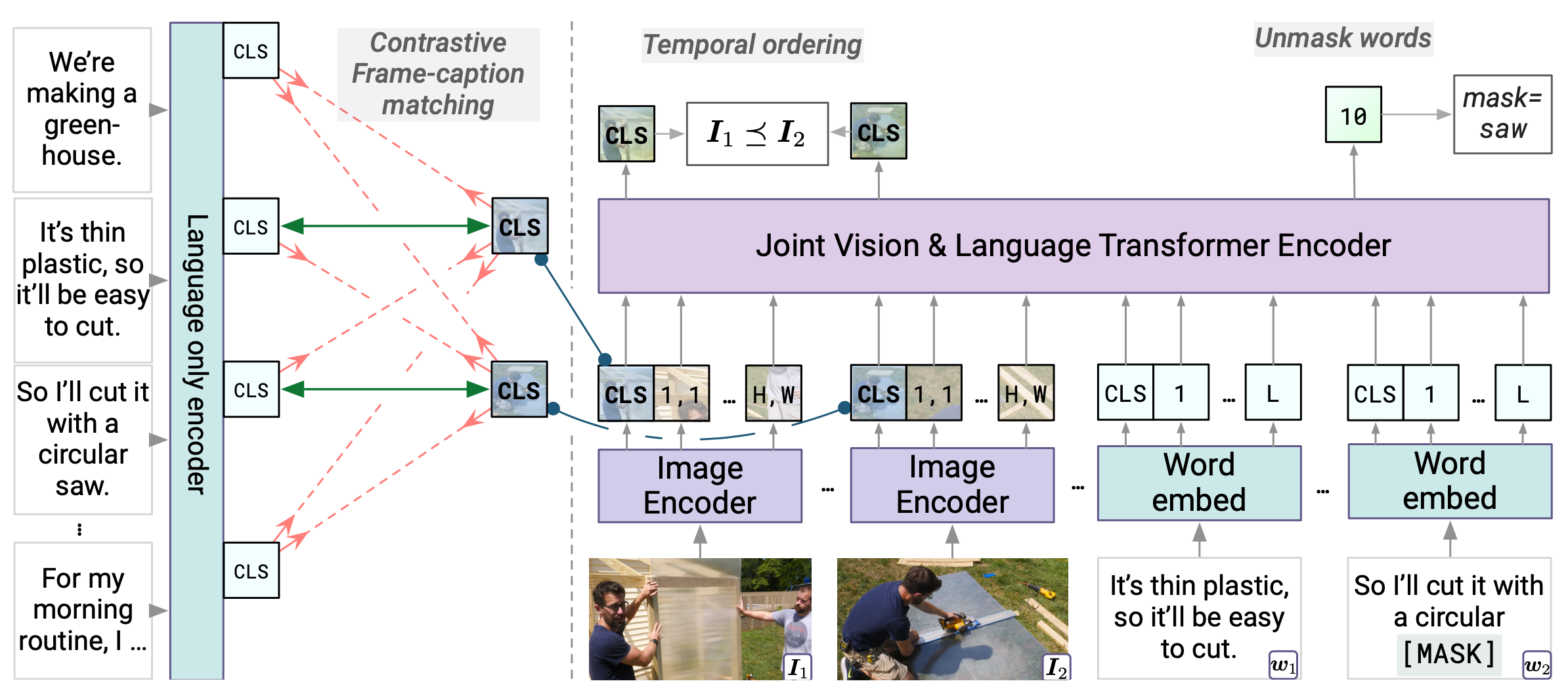
MERLOT(Zellers 等人, 2021)使用了600万油管视频及字幕(YT-Temporal-180M)进行训练。此方法既学习了空间信息(每一帧),也学习了时间信息(视频级别)的目标。经过微调之后,它在VQA以及视觉推理任务上的表现非常好。
每个视频$\mathcal{V}$被分为多个片段$\{ s_t \}$,每个片段$s_t$中包含了从片段中间的时间戳位置上抽取出来的一张图片以及相关的$L=32$个相关字幕的tokens。图片使用预先准备的一个编码器进行编码,单词使用了一个已知的词嵌入表示。而后,这两种表示通过一个联合的视觉-语言transformer进行联合编码。
MERLOT包含了三个学习目标:
- 掩码语言模型(MLM)非常有效,特别是在视频中,人们的语言都比较随意,因此字幕中一般会包含较多的重复以及填充词
- 对比帧标题匹配(Contrastive frame-caption matching):此目标函数仅使用了视觉-语言联合transformer的语言部分。每一帧$I_t$与其匹配的标题$w_t$视为正样本,否则视为负样本
- 时间重排(Temporal reordering):随机抓取$i$帧,使用一个特定的位置编码替换他们的片段位置编码。这样可以让学习器学习到片段所在位置,可以将打乱的片段重新排列为正确的顺序。实际的损失函数反映了每一个 (片段$t_i$, 片段$t_j$)对的先后顺序,即判断是否$t_i \gt t_j$。
对比实验发现以下几点比较重要:
- 使用视频而非图片进行训练
- 提高训练集的大小以及多样性
- 使用多类目标函数来鼓励全栈、多模态推理
Flamingo(Alayrac 等人, 2022)视觉语言模型可以使用文本与图片/视频的交错信息作为输入,而输出自由文本。Flamingo 通过一个基于transformers的映射模块将预训练语言模型与预训练视觉编码器(比如:CLIP 图片编码器)连接起来。为了更加有效地利用视觉信息,Flamingo 中使用了一种基于Perceiver的结构来根据输入的视觉特征生成上百个tokens。而后,使用交叉注意力层将视觉信息融合到语言解码过程中去。训练目标使用了自回归的NLL损失函数。
- 图片/视频的视觉编码器所输出的时空特征会作为Perceiver重采样器的输入,以生成固定长度的视觉tokens
- 语言模型(参数固定)与新初始化的交叉注意力层进行交叉组合,这样语言模型就可以基于视觉tokens的特征信息来生成文本了
Flamingo与ClipCap类似,在训练期间,预训练模型参数都是固定的。因此,Flamingo的训练仅用于将现有强大的预训练语言、视觉模型粘合在一起。与ClipCap不同的是,ClipCap将图片嵌入表示简单地用作语言模型的输入前缀,而Flamingo使用带门控制的交叉注意力层来混合图片信息。此外,Flamingo使用了更多的训练数据。

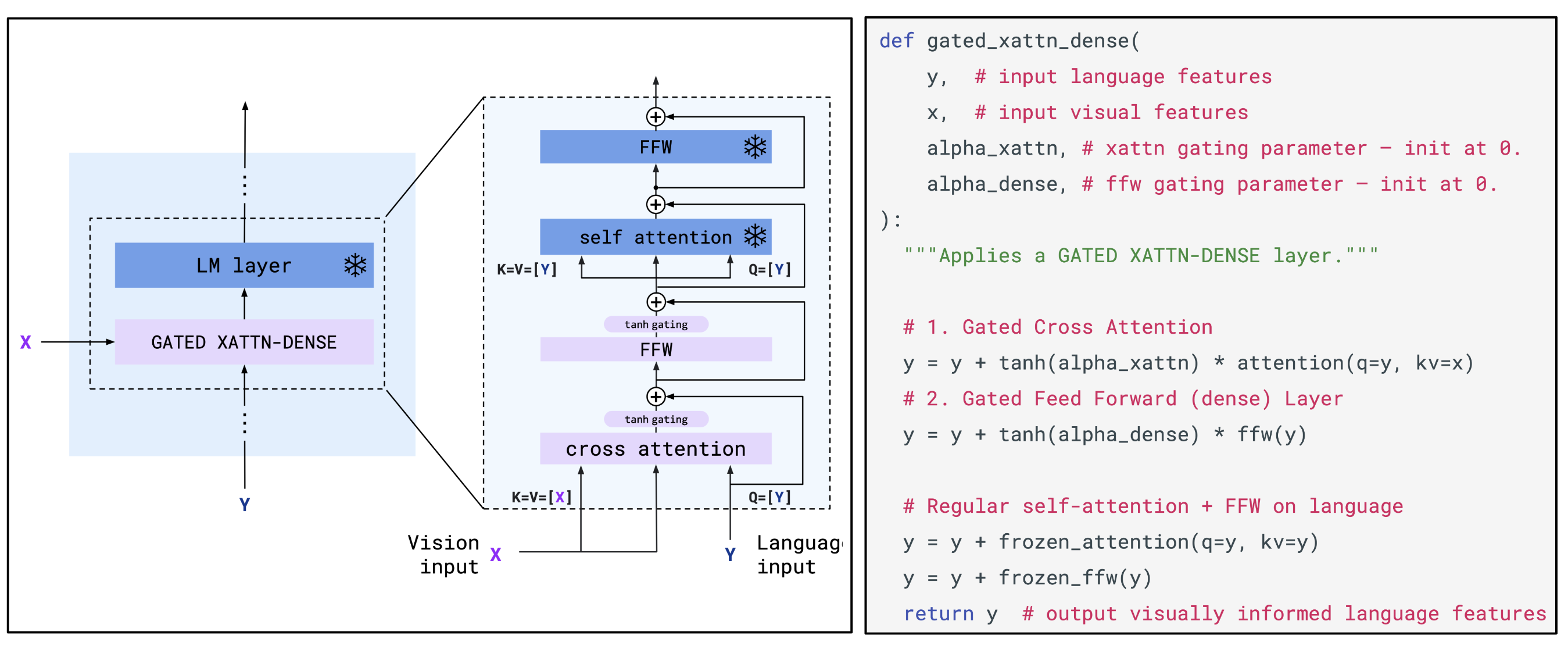
为了更加容易处理文本与图片的交叉信息,Flamingo 中的掩码(masking)被设计为如下工作方式:文本tokens仅注意其前面的最后一张图片,这就大大减少了某个特定文本可以看到的视觉tokens的数量。研究者们发现这相比于让文本可以接触到其之前的所有视觉tokens,模型可以工作得更好。此外,由于后面的文本编码器有一个自注意力层,这样的设计并不会让文本无法与之前的图片进行“交互”。这种设计可以可以让任意数量的图片在同一上下文中被处理。
Flamingo的训练集为从网络上爬取的4300万页面数据,数据集命名为MultiModal MassiveWeb, (M3W)。数据集里包含了文本与图片的交叉信息。此外,Flamingo也在图片/文本对以及视频/文本对数据集(包含:AliGN, LTIP 和 VTP, )上进行了训练。
从网络爬取的数据预处理流程包括:
- 在页面视觉输入的部分插入
<image>标签,在句子开始处插入<BOS>,在一大段数据(end of chunks)后插入<EOC>(在文档末尾以及任意图片标签之前总是插入) - 从每个页面文档中,他们随机采样$L=256$个tokens 序列以及包含在其中的最多$5$张图片(如果序列中包含多于$N$张图片,则取前$N$张;如果不够,则填充到$N$张)
- 使用函数$\phi: [1,L] \to [0,N]$来记录图片位置,若某个文本token对应位置之前没有图片,那么记零
由于Flamingo的训练使用了三种不同的数据集,它的损失函数为不同数据集特定损失函数的加权。调整不同数据集的权重对于模型的最终性能表现至关重要。在实际操作中,他们没有直接使用循环使用不同数据集的数据的方式进行训练,而是在每个数据集中采样一个batch数据,然后将从不同数据集中采样得到的样本计算而来的梯度进行加权求和,再进行一步更新。不同类型数据集中的数据的梯度累加可以视为一种稳定训练的方法,它可以降低梯度更新之间的方差。
由于Flamingo支持任意图片、文本的交叉输入,它在测试阶段可以支持few-shot学习。并且输入信息越丰富,得到的最终性能越好。
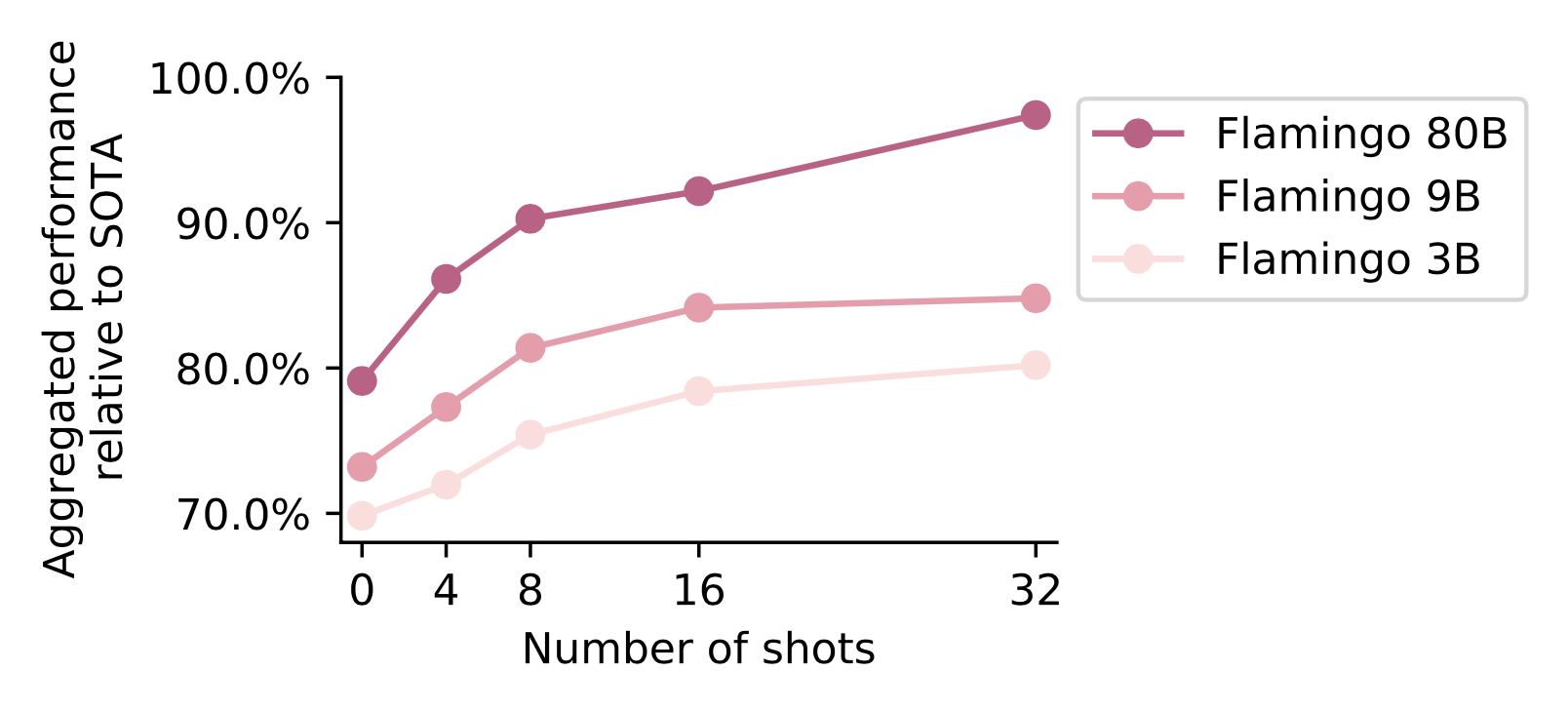
Falmingo即使不进行任何微调,仅用few-shot提示(few-shot prompting),它的性能就可以在6/16个任务上超过微调过的SoTA模型。虽然微调Flamingo的代价十分昂贵,调整它的参数十分困难,但是微调确实可以带来更好的性能表现。
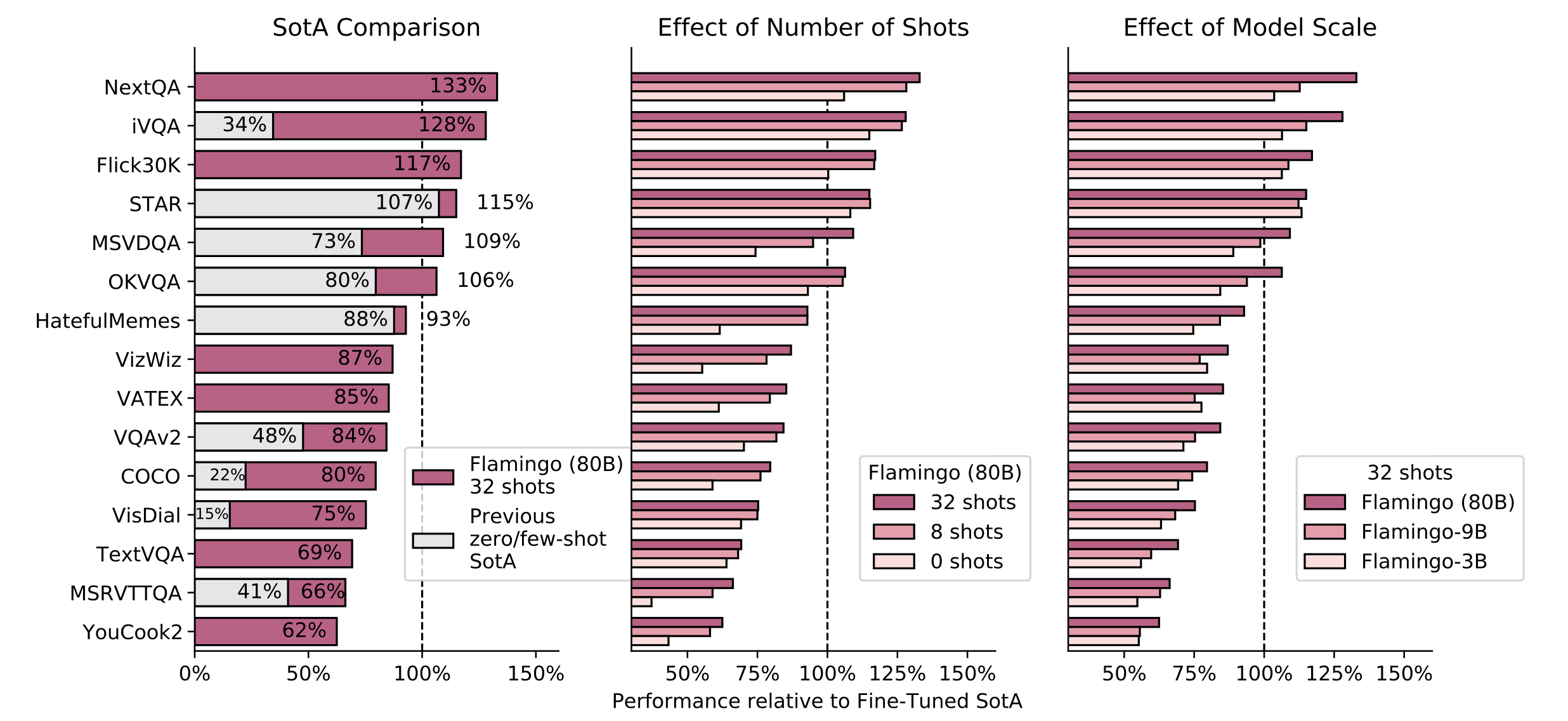
Coda (Contrastive Captioner;Yu & Wang 等人, 2022)汲取了对比学习及图片标题生成两者的长处。它的训练既使用了基于CLIP风格表征的对比损失,又使用了基于图片标题生成任务的生成损失,最终在多个多模态zero-shot迁移任务上取得了SoTA的性能。
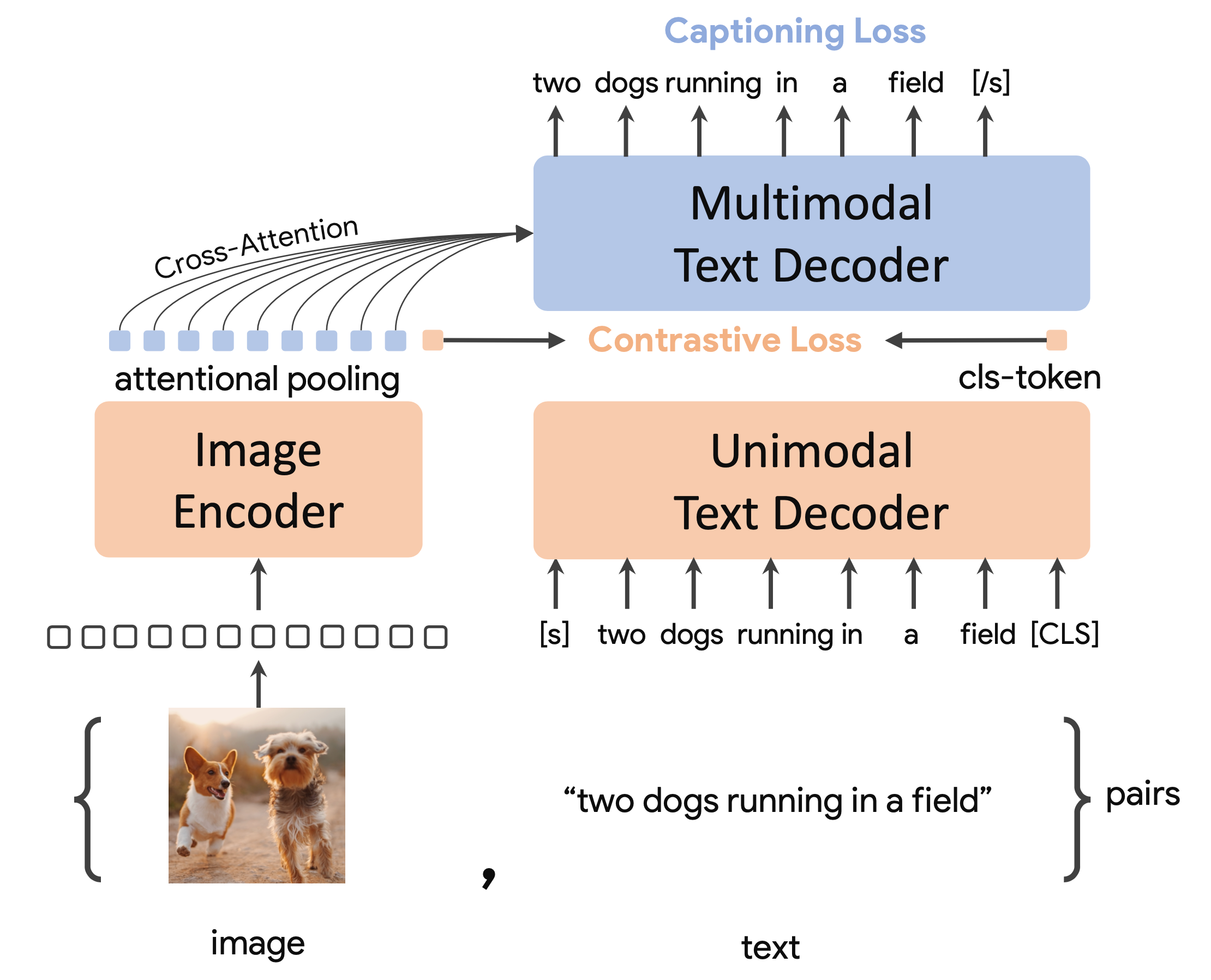
CoCa使用了web级alt属性文本数据集ALIGN和JTB-3B数据集(将labels视作文本)从零开始训练。
CoCa包含两个主要组成部分。最终的损失函数为以下两个的加权和,对应权重分别为:$\lambda_{cap}=2.0, \lambda_{con}=1.0$:
- $\mathcal{L}_{con}$- 对偶编码器对比学习用于优化对称对比学习损失(类似CLIP)
- $\mathcal{L}_{cap}$- 基于隐层的图片编码特征来进行解码,解码得到图片对应的标题,此处使用自回归损失。文本解码器被解偶为两部分:单模态与多模态;一个比较好的平衡点是将解码器分成两半:
- 底层的单模态部分使用自注意力机制对输入文本编码进行编码
- 顶层的多模态部分对视觉编码器的输出同时使用自注意力机制与交叉注意力机制
CoCa的性能表现在VQA任务上优于仅使用对比损失的模型,与仅使用字幕的模型相当。实验发现$\mathcal{L}_{cap}$对于zero-shot分类来说是有好处的。
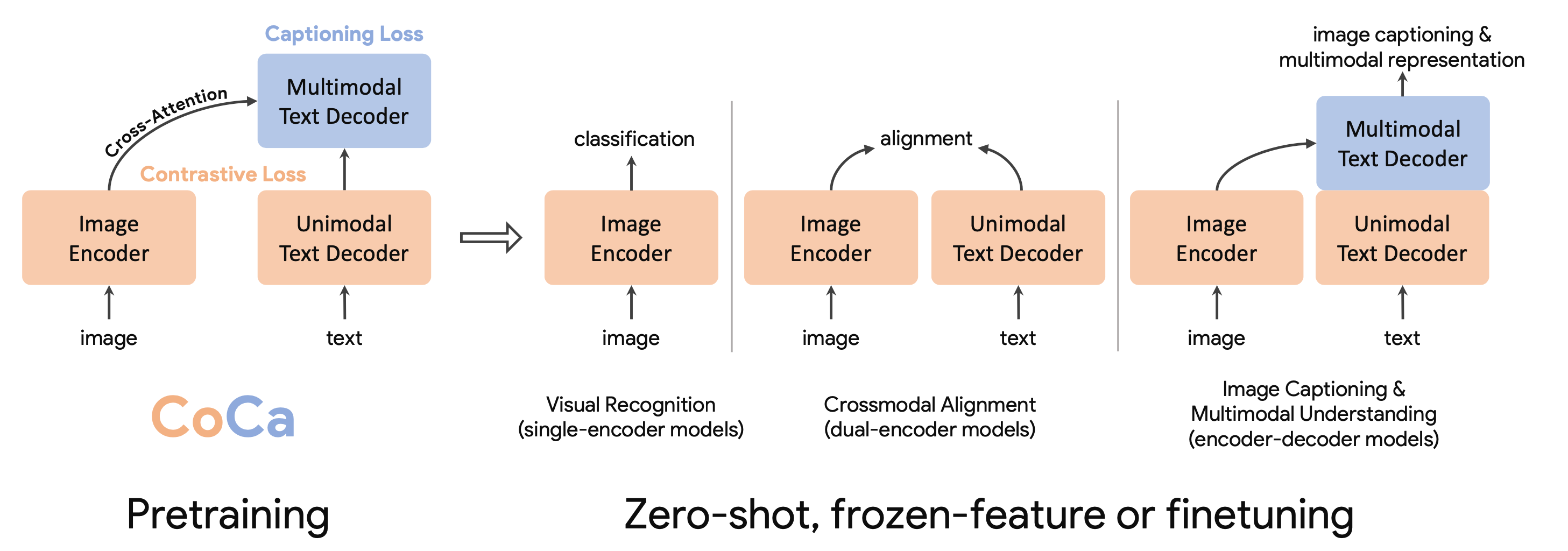
Coca使用了特定任务相关的注意力池化作为一个自然的任务适配器。研究者们发现单一的图片嵌入池化对于视觉识别任务有益,而对嵌入表示进行细粒度的池化对于多模态理解任务(比如VQA)很有帮助。池化器(pooler)是一个多头注意力机制层,它包含了$n_{query}$个查询(queries)(注意$\mathbf{X} \in \mathbb{R}^{L \times d}$,$\mathbf{W}^q \in \mathbb{R}^{d \times d_q}$,$d_k = d_q$),同时输出键(keys)和值(values)。CoCa在预训练过程中,生成损失($n_{query}=256$)与对比损失($n_{query}-1$)均使用注意力池化器。这样可以让模型仅作为一个固定的编码器来使用,仅需学习一个新的池化器来聚合特征。

无二次训练
最后,直接将预训练语言模型与视觉模型缝合使用,而不再进行任何的二次训练来解决视觉语言任务是可能的。
使用视觉评分指导解码
MAGiC(iMAge-Guided text generation with CLIP;Su 等人, 2022)无需任何的微调,根据一个基于CLIP的得分(称为magic score)来指导解码过程,以对下一个token进行采样。
第$t$步的token$x_t$根据下面的等式进行选择。为了避免语言模型中生成崩坏(corrupted generation)现象的产生,token的选择过程中还考虑了模型的置信度与退化惩罚机制(Su等人, 2022)。
$$
\begin{aligned}
& x_t = \arg\max_{v \in \mathcal{V}^{(k)}} \big\{ (1-\alpha) \underbrace{p(v \vert \boldsymbol{x}_{\lt t})}_\text{模型置信度} - \alpha \underbrace{\max_{1 \leq j \leq t-1} { \text{cosine}(h_v, h_{x_j})}}_\text{退化惩罚} + \beta \underbrace{f_\text{magic}(v \vert \mathcal{I}, \boldsymbol{x}_{\lt t}, \mathcal{V}^{(k)})}_\text{magic score} \big\} \\
\text{其中 } & f_\text{magic} ( v \vert \mathcal{I}, \mathbf{x}_{\lt t}, \mathcal{V}^{(k)} )
= \frac{ \exp(\text{CLIP}(\mathcal{I}, [\boldsymbol{x}_{\lt t}:v])) }{ \sum_{z \in \mathcal{V}^{(k)}} \exp(\text{CLIP}(\mathcal{I}, [\boldsymbol{x}_{\lt t}:z])) }
= \frac{ \exp\big({h^\text{image}(\mathcal{I})}^\top h^\text{text}([\boldsymbol{x}_{\lt t}:v])\big) }{ \sum_{z \in \mathcal{V}^{(k)}} \exp\big({h^\text{image}(\mathcal{I})}^\top h^\text{text}([\boldsymbol{x}_{\lt t}:z])\big) }
\end{aligned}
$$
其中$\mathcal{I}$为输入图片;$\mathcal{V}^{(k)}$包含top-$k$个可能的tokens,由语言模型$p$输出;$x_{\lt t}$指的是在时间$t$之前已生成的tokens;$h_v$为token$v$的表征,由语言模型根据$x_{x \lt t}$与$v$计算得来;$h^{image}(\cdot)$与$h^{text}(\cdot)$为由CLIP的图片与文本编码器生成的嵌入表示。
MAGiC相比于其他无监督方法性能表现还不错,但是与监督学习方法相比仍有较大差距。
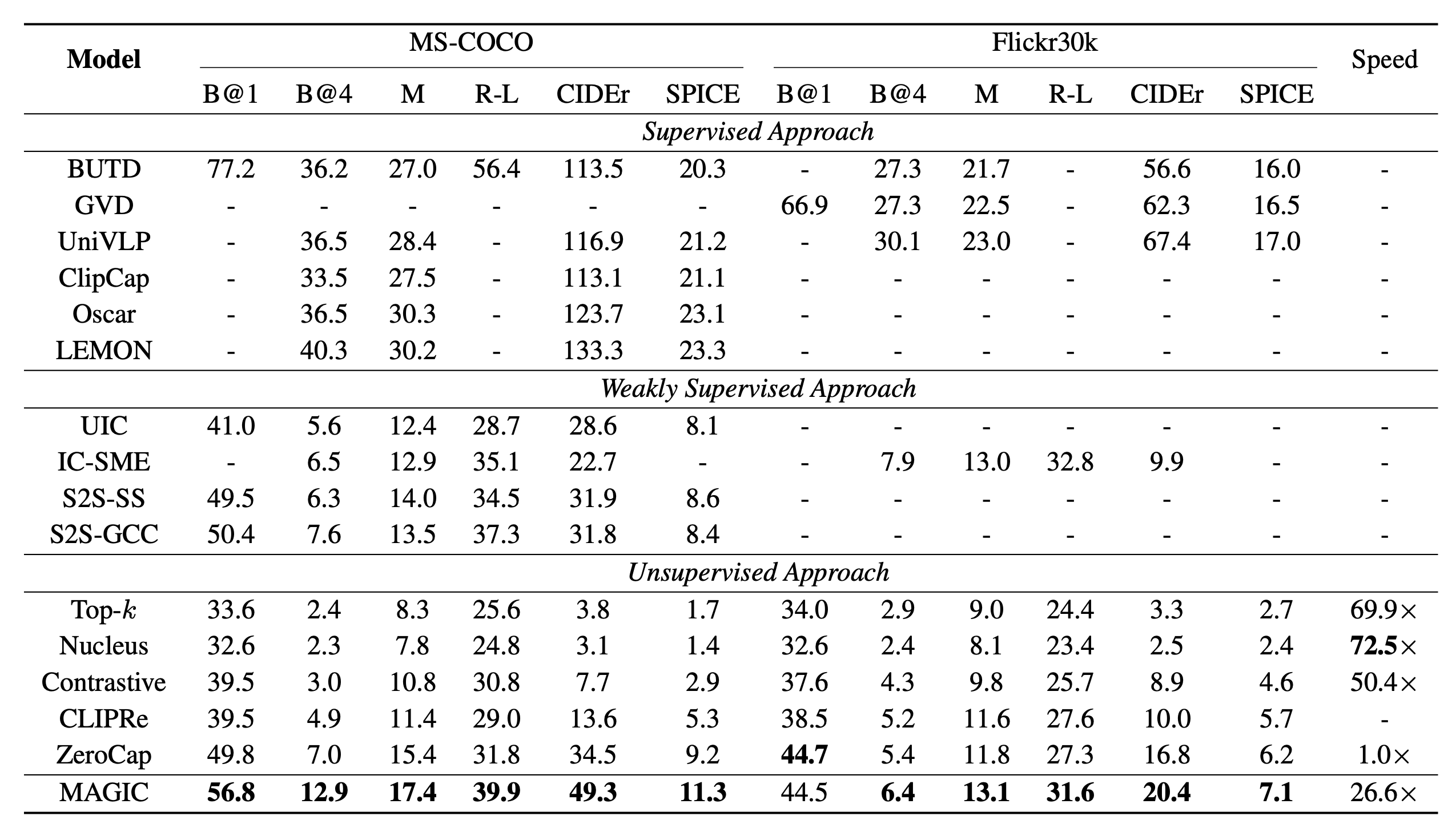
使用语言作为交流接口
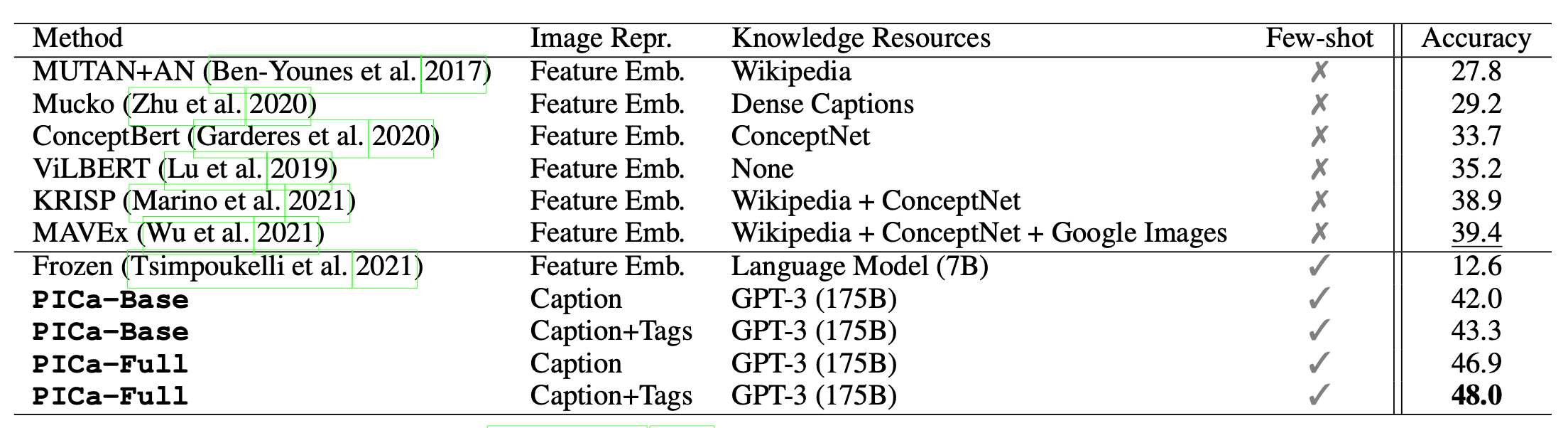
对于基于知识(knowledge-based)的VQA任务,PICa(Prompts GPT-3 via the use of Image Captions;Yang 等人, 2021)首先将图片转化为标题或者标签,而后再用few-shot样本来指导GPT3生成回答。图片的标题或标签由一些现有模型(VinVL)或者Azure Tagging API来输出。此外,这里GPT3被用作一个无结构的、隐式的知识库。

PICa 探索了两个改善few-shot样本的方法,以得到更好的结果:
- 上下文实例(in-context examples)是根据他们与问题的相似度(使用CLIP嵌入表示)来进行选择的
- 多询问(multi-query)聚合用于对模型进行多次提示(prompt)来获取多个答案,最后概率最大的那个会被选择
这个简单的方法仅用16个实例即将在OK-VQA上的得分提升了8.6个点,并且在VQAv2上也取得了不错的性能。
Socratic Models(SM)(Zeng 等人, 2022)是一个用于将多个不同模态的预训练模型组合到一起的一个框架。它使用了语言提示(prompting)方法,并且无需进行进一步的训练。这里语言被看作一种多个模型之间可以交换信息的中间表征。它的核心思想是:使用多模型多模态提示(multi-model multimodal prompting)。非语言模型的输出被插入到语言提示(language prompt)中去,给语言模型来进行因果推理。
让我们来看一个具体的例子。给定一个第一人称的视频(图片+音频),SM可以利用文本转文本的语言模型(LM)、图片转文本的视觉语言模型(VLM)以及音频转文本的音频语言模型(ALM)来生成个人行为活动的一个描述。
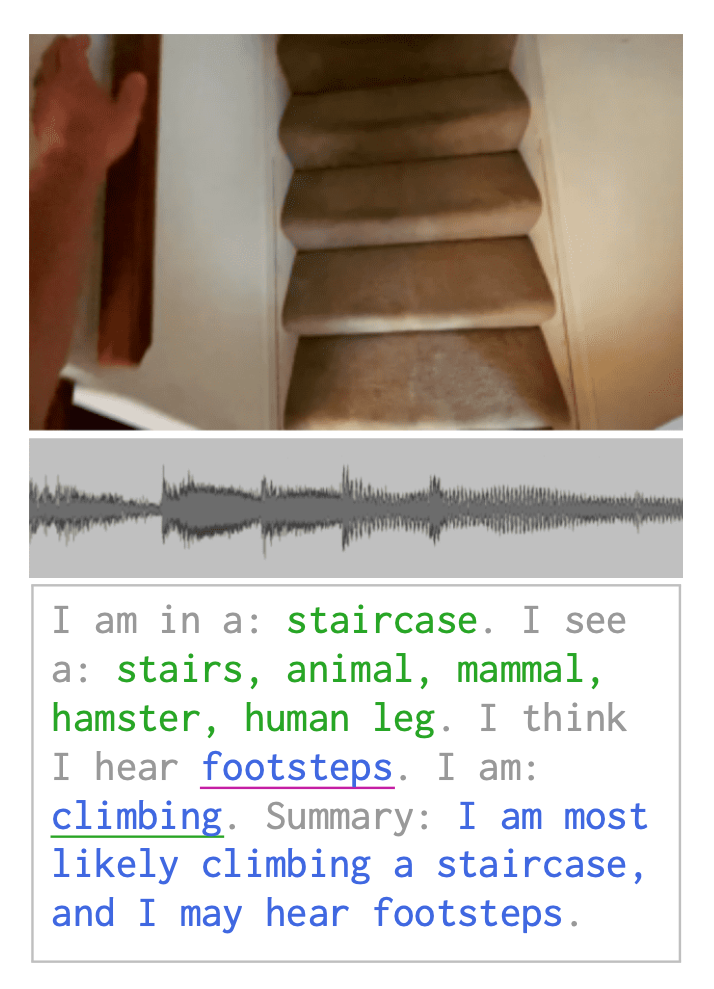
- VLM 检测视觉实体
- LM提示可能被听到的语音
- ALM选择最可能的语音
- LM提示可能的活动
- VLM对可能的活动进行概率排序
- LM生成互动概要
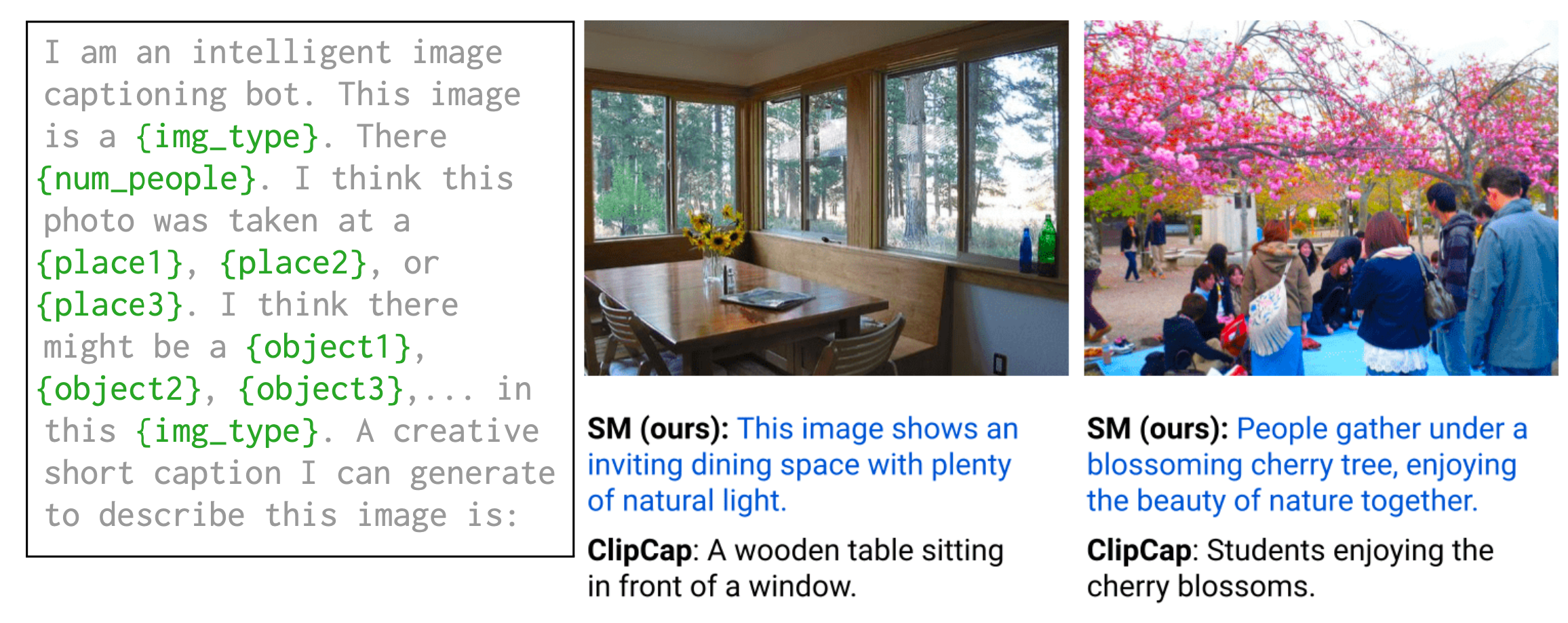
SM可以首先使用VLM来对地点、实体对象、图片类型以及任务数量等进行零样本预测,而后再将VLM填充的语言提示输入到因果LM以生成候选标题。Socratic方法在图像标题生成上与ClipCap仍有差距,但是它不需要进行任何的二次训练,因此看起来还是非常不错的。
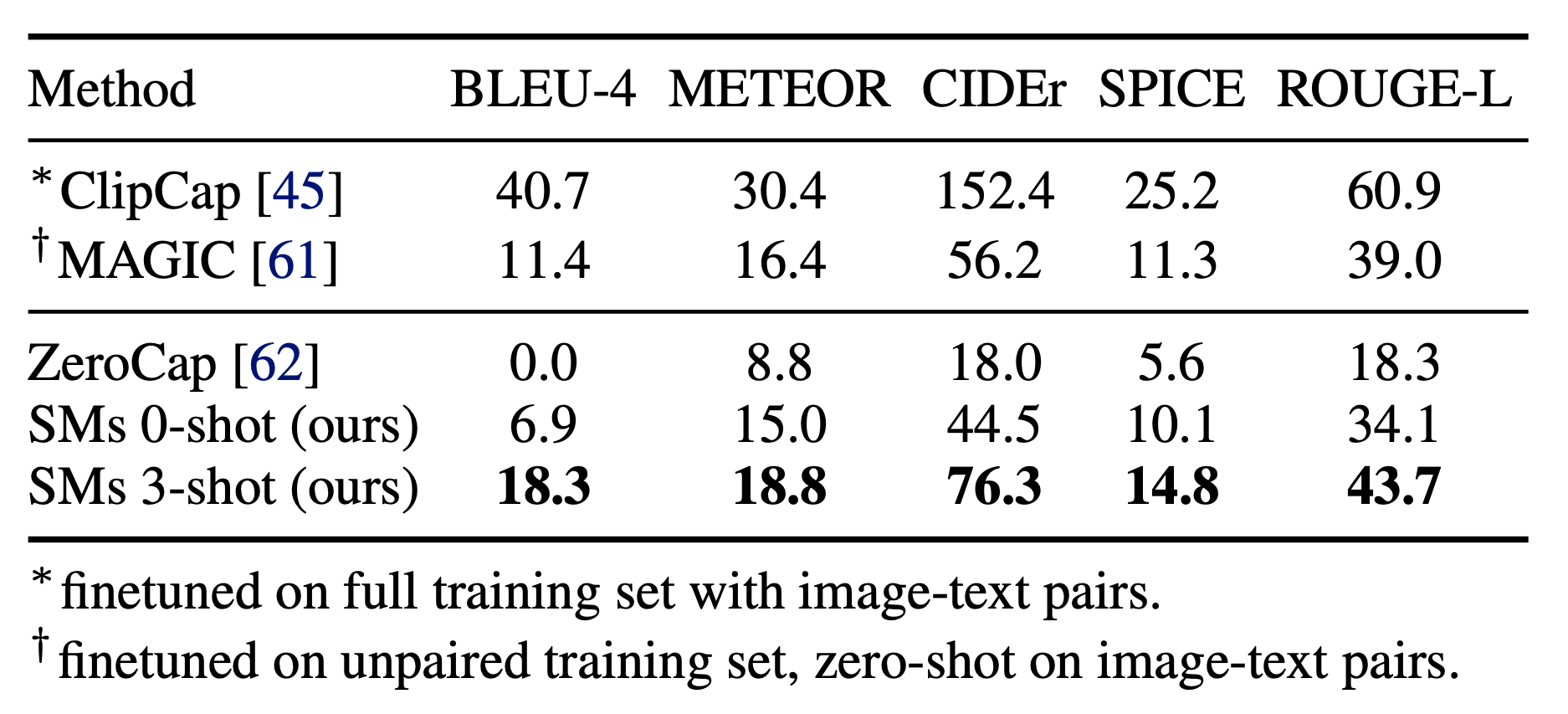
SM 框架非常的灵活,也可以被应用到许多更加复杂的任务上去。例如,第一人称视频感知(用户输入+VLM+LM+ALM)任务以第一人称视频作为输入,以进行(1)内容概述,(2)自由问答,以及(3)预测。

数据集
图片标题数据集
- MS COCO(Chen 等人, 2015)包含328k的图片,每张图片对应5个独立的标题
- NoCaps(Agrawal 等人, 2019)被设计用于衡量在不同类别与概念下的泛化性。其中,域内图片数据包含了仅在COCO数据集中出现过的类别;近域(near-domain)数据集包含了COCO中有的图片类别,也包含了新的类别;域外数据(out-of-domain)仅包含新类别的数据
- Conceptual Captions(Sharma 等人, 2018) 中包含了三百万个图片-标题对。这些数据是从网络页面上爬取的,后经过了预处理。为了专注于概念,该数据集中的特定实体使用一些泛化的表示进行了替换(比如:一个政治家的名字被替换为“政治家”)
- Crisscrossed Captions (CxC)(Parekh 等人, 2021) 包含了247,315个在图片对、标题对以及图片-标题对(包含正负相关的样本)上的人工手动注解
- Concadia(Kreiss 等人, 2021) 是一个基于维基百科的数据集。它包含了96,918张带有英文描述、标题以及上下文的图片
图片-文本对数据集
(*):非公开数据集。
- ALIGN(Jia 等人, 2021) 中包含了18亿图片以及对应的文本。这个数据集非常大,但是也包含了大量的噪声,仅进行了最小的基于频率的过滤
- (*)LTIP(Long text & image pairs;Alayrac 等人, 2022):3.12亿图片及对应的标题描述
- (*)VTP(Video & text pairs;Alayrac 等人, 2022):2700万短视频(每个22s左右)及其对应的标题描述
- (*)JFT-300M | JFT-3B 是谷歌内部数据集,它包含了300M/3B图片,通过一个半自动化的管道进行注释(注释的标签包含了大约3万个类别,这些类别之间是一个层次结构)。因此,这些数据中包含了噪声
评估任务
视觉问答
给定一张图片与一个问题,此任务是正确回答提问。
- VQAv2(Goyal 等人, 2017) 包含了100万+的关于200k图片的问题(图片来自COCO)
- OK-VQA(Marino 等人, 2019) 包含了14k需要外部知识(比如从维基百科获取)的开放性问题
- A-OKVQA:OK-VQA的增强版,其中的问题与OK-VAQ无重叠
- TextVQA(Singh 等人, 2019)包含了28,408图片上的45,336个问题,需要在文本上进行推理才能进行回答
- VizWiz(Gurari 等人, 2018) 中包含了31,000个来自盲人的视觉问题,每个盲人使用手机拍摄照片,并且记录了相关的口头问题。每个视觉问题还搜集了10个通过众包得到的答案
视觉语言推理
- VCR(Visual Commonsense Reasoning;Zellers 等人, 2018)中包含了290k个多选问答题,这些问题来自110k个电影场景,仅关注视觉常识问题
- NLVR2(Natural Language for Visual Reasoning;Suhr 等人, 2019) 包含100k+的句子对样本及其对应的网络图片。此任务为决定某个自然语言标题是否是关于某对图片的一个真实描述,这些问题注重语义多样性
- Flickr30K(Jia 等人, 2015)中包含了30k张从Flickr搜集而来的图片以及250k个注解。此任务是为一个句子中的特定范围的内容选择图片中的特定区域
- SNLI-VE(Visual Entailment;Xie 等人, 2019)基于SNLI与Flickr30K数据集构建。这个任务是推理图像前提与文本假设之间的关系
视觉问答与理解
- MSR-VTT(MSR Video to Text;Xu 等人, 2016)中包含了10k网络视频剪辑,共41.2小时及200k剪辑句子对。该任务将视频转换为文字
- ActivityNet-QA(Yu 等人, 2019) 中包含了58000个人工注解的问答对。这些问答都是关于ActivityNet数据集中的视频的
- TGIF(Tumblr GIF;Li 等人, 2016)中包含了100k动态GIFs图片以及120k个对应图片的描述(数据搜集于2015年5月到6月间Tumblr上的公开数据)
- TGIF-QA中包含了165k问答对(关于TGIF数据集中的GIFs图片)
- LSMDC(Large Scale Movie Description Challenge;Rohrbach 等人, 2015)中包含了118,081个从202个电影中剪辑而来的视频片段。每个视频有一个字母,可以从电影脚本中提取,也可以从为视障人士转录的视频描述服务中提取
- TVQA(Lei 等人, 2018) /TVQA+(Lei 等人, 2019)是一个基于6个流行的TV秀(Friends, The Big Bang Theory, How I Met Your Mother, House M.D., Grey's Anatomy, Castle)的视觉问答数据集。它包含了21.8k个视频片段相关的152.5k个问答对(覆盖了大约460小时的视频)
- DramaQA(Choi 等人, 2020)是一个大型的视觉问答数据集。它基于韩国流行的TV秀 “Another Miss Oh”。这个数据集中包含了4个级别难度的问答以及多个级别的以人物为中心的故事描述
- VLEP(Video-and-Language Event Prediction;Lei 等人, 2020) 中包含了来自10,234个不同电视节目和油管vlog视频剪辑的28,726个未来事件预测示例(及其他们的逻辑依据)
参考文献
[1] Li et al.“VisualBERT: A Simple and Performant Baseline for Vision and Language."arXiv preprint:1908.03557 (2019).
[2] Wang et al.“SimVLM: Simple Visual Language Model Pretraining with Weak Supervision."ICLR 2022.
[3] Aghajanyan, et al.“CM3: A Causal Masked Multimodal Model of the Internet."arXiv preprint arXiv: 2201.07520 (2022).
[4] Tsimpoukelli et al.“Multimodal Few-Shot Learning with Frozen Language Models."NeuriPS 2021.
[5] Mokady, Hertz & Hertz.“ClipCap: CLIP Prefix for Image Captioning."2021.
[6] Chen et al.“VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning."arXiv preprint arXiv:2111.09734 (2021).
[7] Luo et al.“A Frustratingly Simple Approach for End-to-End Image Captioning."arXiv preprint arXiv:2201.12723 (2022).
[8] Zellers et al.“MERLOT: Multimodal neural script knowledge models."NeuriPS 2021.
[9] Alayrac et al.“Flamingo: a Visual Language Model for Few-Shot Learning."arXiv preprint arXiv:2204.14198 (2022).
[10] Yu & Wang et al.“CoCa: Contrastive Captioners are Image-Text Foundation Models."arXiv preprint arXiv:2205.01917 (2022).
[11] Yang et al.“An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA."arXiv preprint arXiv:2109.05014 (2021).
[12] Su et al.“Language models can see: Plugging visual controls in text generation."arXiv preprint arXiv:2205.02655 (2022).
[13] Zeng et al.“Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language."arXiv preprint arXiv:2204.00598 (2022).

更多推荐