
此文提出了著名的PPO算法,由谷歌 Open AI 于17年发布,对于深度强化学习领域产生了巨大的影响。在此之前,Natural Policy Gradient 算法解决了策略梯度算法的收敛性问题,但是此算法需要计算二阶导矩阵,在实际使用中性能受限,扩展性差。现有许多研究研究工作都是围绕如何通过近似二阶优化算法来降低算法复杂度。PPO算法采用了一个不太一样的方法,它没有引入一个强约束,而是将约束项作为目标函数中的一个惩罚项。这样就可以使用一阶优化算法来进行模型优化,大大降低了算法复杂度。
文章目录
简介
近年来,许多研究者提出了不同的方法来将神经网络来应用到强化学习中去。但是这些方法都有各种各样的缺点,比如数据利用率低、复杂性高等等。本文在强化学习中现有策略梯度算法的基础上提出了一种改进的算法,思路与之前的TRPO(Trust Region Policy Optimization)算法的思路差不多,但是比其更加简单实用。标准的策略梯度算法主要采用on-policy的策略,即样本采样依赖于当前策略。因此样本被训练一次后,策略改变,就需要重新采样,样本利用率低。本文提出的算法(PPO, Proximal Policy Optimization)采用重要性采样方法(off-policy),数据采样不依赖于当前策略。因此,允许使用单个样本进行多轮的训练,可以增加数据利用的效率。更重要的是,该算法可以使用一阶优化算法(比如:SGD/Adam)等等来进行优化,实现起来更加容易,而且可以达到甚至超越之前TRPO的性能。
背景知识
强化学习环境中一般有几个基本概念:
- 状态 $s$
- 策略 $\pi_{\theta}$:策略一般以状态为输入,输出一个行为$a$
- 行为 $a$:由策略输出
- 奖励 $r$:奖励由环境给出
- 价值函数 $v$:用于衡量一个状态的价值
基本工作流程如下图所示:在$t$时刻,环境会给出一个状态表示$s_t$,策略函数以状态为输入输出一个需要执行的行为$a$,环境会去执行行为$a$,并且输出奖励$r_t$、执行后的状态$s_{t+1}$。
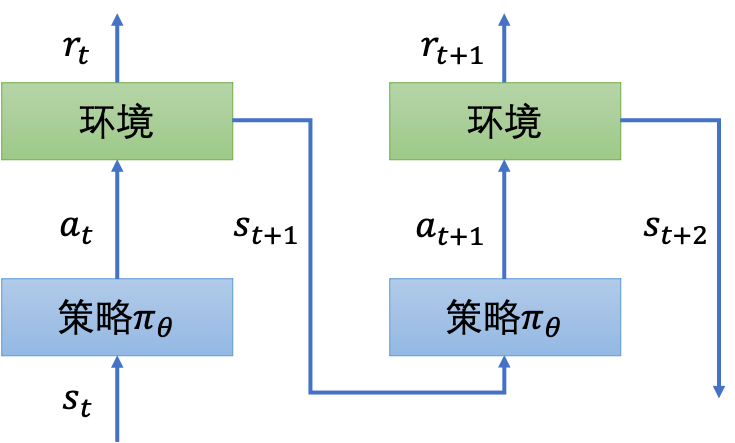
这样每次与环境互动,可以得到一个互动序列:
$$ \tau = (s_0, a_0, r_0, s_1, a_1, r_1, \ldots, s_t, a_t, r_t) $$
我们称这一个序列为一个路径。
当行为是一些离散状态时,一般我们在实现的时候,会将策略$\pi_{\theta}$实现为一个解决分类问题的神经网络(如下图所示),该神经网络以环境状态$s$为输入,以采取各行为$a$的概率为输出。

策略梯度算法
策略梯度(PG, Policy Gradient)算法常使用下面的目标函数(进行梯度提升,一般实现时取负以使用梯度下降优化算法):
$$ L^{PG}(\theta) = \hat{E_t}\left[ log\ \pi_{\theta} (a_t|s_t)\hat{A_t} \right] $$
其中$\hat{A_t}$为在$t$时刻的优势预测值(Advantage Function)。
一般在实现的时候,我们会使用环境给出的$r_0, r_1, \ldots, r_t$来计算$\hat{A_t}$的预计值,使用神经网络来模拟策略$\pi_{\theta}(a_t|s_t)$,来计算采用行为$a_t$的概率。
策略梯度算法通常会被实现为一个on-policy算法。在On-policy算法中,每采集一次样本一般只使用该样本进行一次梯度更新。虽然也可以使用采集到的样本跑多轮学习(进行多个epoches训练),但是实际很可能会导致一个较大的梯度更新,实际训练效果并不好。
在on-policy算法中,由于行为$a$的产生依赖于当前的策略$\pi$,而每次训练一轮后,策略$\pi$就变化了,因此必须重新采样进行训练。如果我们从一个较差的状态$s$开始,并且初始策略$\pi_{\theta}$也较差,那么训练过程就会相当痛苦。训练过程中,生成的样本可能一直非常差,导致模型收敛速度极慢。为此可以采用off-policy方法。
Off-policy方法
Off-policy算法不依赖于当前的策略$\pi$来生成需要执行的行为$a$。采样时,我们可以采用任意固定的策略$\pi_{\theta^{\prime}}$来进行采样。由于所采样本与当前训练的策略$\pi_{\theta}$无关,因此,采样、训练可以并行,而且采集到的样本可以进行多轮的训练,以加快模型的训练。这就是重要性采样方法(importance sampling)。
离线策略算法的目标函数为:
$$ L^{PG}_{off} = \hat{E_t}\left[ \cfrac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta^{\prime}}(a_t|s_t)}\hat{A_t} \right] $$
由于重要性采样要求所采样的分布与我们实际计算期望的分布差别不能太大,在$L_{off}^{PG}$中也就是$\pi_{\theta}$与$\pi_{\theta^{\prime}}$分布不能相差太大,实际训练时才能效果才能更稳定。因此,对于收益目标函数$L_{off}^{PG}$必须添加一个约束项来让限制两个分布之间的距离。
TRPO (Trust Region Policy Optimization)
在TRPO算法中,引入了KL散度来衡量两个分布之间的距离。对于$L_{off}^{PG}$进行了如下约束:
$$ \hat{E_t}[KL[\pi_{\theta^{\prime}}(\cdot|s_t), \pi_{\theta}(\cdot|s_t)]] \le \delta $$
此带约束项的优化问题可以用共轭梯度算法求解。
由于TRPO算法中需要近似计算二阶导数,算法较为复杂,那么有没有更简单的方法不需要计算二阶导数呢?这就是本文的motivation。
算法详解
一种直观的解决方案就是直接将约束项作为目标函数的惩罚项直接进行一阶算法优化,目标函数如下:
$$ \hat{E_t}\left[ \cfrac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta^{\prime}}(a_t|s_t)}\hat{A_t} - \beta KL[\pi_{\theta^{\prime}}(\cdot|s_t), \pi_{\theta}(\cdot|s_t)] \right] $$
TRPO中没有使用该方法的原因是$\beta$值难以选择。
文中提出了两种解决方案:截断目标函数 和 自适应惩罚系数
截断目标函数
我们使用$r_t({\theta})$表示:
$$ r_t(\theta) = \cfrac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta^{\prime}}(a_t|s_t)} $$
显然$r_t(\theta^{\prime}) = 1$, 那么本文采用的截断目标函数为:
$$ L^{CLIP}(\theta) = \hat{E_t}\left[min(r_t({\theta}) \hat{A_t}, clip(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A_t}) \right] $$
论文中给出的$\epsilon=0.2$,上述目标函数中$min$的第一项为原来的目标函数,我们记为$L^{CPI}$(CPI: Conservative Policy Iteration);第二项将比率$r_t(\theta)$限制在了$(1-\epsilon, 1+\epsilon)$之间。最后的目标函数为这两者的较小的那一个。显然当$clip(\cdot)$在$1$附近时,目标函数不变。当$clip(\cdot)$过大时,如下图所示,分两种情况讨论:$A>0$与$A<0$。

$A>0$时,表示收益为正,为了优化后得到的收益变高,我们希望系数越大越好。但是为了防止$r_t(\theta)$过大,$\hat{A_t}$的系数被限制在了$<1+\epsilon$的范围内,这样参数不会更新太大。

同样$A<0$时,收益为负,此时我们希望参数越小越好(这样负收益就变小了),但是为了防止过小,将系数限制在$>1-\epsilon$的范围内。
自适应惩罚系数
该方法,采用动态调整$\beta$的方法来优化下面的目标函数:
$$ \hat{E_t}\left[ \cfrac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta^{\prime}}(a_t|s_t)}\hat{A_t} - \beta KL[\pi_{\theta^{\prime}}(\cdot|s_t), \pi_{\theta}(\cdot|s_t)] \right] $$
$\beta$的调整方法是,首先计算$d=\hat{E_t}[KL[\pi_{\theta^{\prime}}(\cdot|s_t), \pi_{\theta}(\cdot|s_t)]]$,然后:
- 如果$d < d_{target} / 1.5$, $\beta \leftarrow \beta / 2$
- 如果$d > d_{target} 1.5$, $\beta \leftarrow \beta 2$
直观理解就是:
- $d < d_{target} / 1.5$表明两个分布太像了,说明$KL$散度那一项被优化太多了,因此此时需要把系数减小,所以$\beta \leftarrow \beta / 2$
- $d > d_{target} 1.5$表明两个分布差异太大了,说明优化力度不够,因此需要把系数增大,所以 $\beta \leftarrow \beta 2$
添加 value 偏差惩罚与 exploration
论文中除了上述的目标函数外,还提出可以添加其它项来进一步优化目标函数。
第一,在目标函数中添加与值函数相关的惩罚项:
$$ L_t^{VF}(\theta) = (V_\theta(s_t) - V_t^{target})^2 $$
其中$V_{\theta}$为值函数,一般可以通过与策略网络共享其中的一些参数,只在最后一层采用不同的全连接层来得到值函数预测$V_\theta(s)$,本文的实验采用了独立的值函数网络。
第二,在目标函数中添加与 exploration 相关的激励项:
$$ S[\pi_\theta](s_t) $$
$S$项主要是为了确保样本进行了足够的探索,具体可以参考[2]。
最终的目标函数为:
$$ L_t^{CLIP+VF+S}(\theta) = \hat{E_t}\left[L_t^{CLIP}(\theta) - c_1L_t^{VF}(\theta) + c_2S[\pi_\theta](s_t) \right] $$
其中$c_1, c_2$为超参数,可以根据实际调整。
优势函数值A计算
$\hat{A_t}$的计算方式为:
$$ \hat{A_t} = \delta_t + (\gamma\lambda)\delta_{t+1} + \cdots + (\gamma\lambda)^{T-t+1}\delta_{T-1} $$
其中:
$$ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) $$
此处$V$表示值函数,可以将状态$s$直接带入到代表值函数的神经网络中得到;$\gamma/\lambda$为两个参数,常用值比如$0.9, 0.99$等。
实验对比
本文使用了Open AI Gym 中的7个模拟机器人的任务进行实验,每个任务进行了100万步(timesteps)的训练。策略网络使用了两个隐层大小为64的全连接MLP网络,使用$tanh$为激活函数,值函数与策略网络没有共享参数,此外没有使用前面提到的exploration项$S$。最终得分进行了标准化,随机策略得分为0,目前最高得分归一化为1。最终结果如下表所示:
其中,显然不限制分布差异的$L^{CPI}$得分为负,比随机策略还要差。使用KL散度作为惩罚项的方法最优得分没有使用截断的算法高。最优截断算法$\epsilon=0.2$。
文中还给出了与其它算法的比较,比如$A2C/CEM/TRPO$等等,在大多数实验中,PPO(截断算法)都能给出较好的结果。具体大家可以参考原文。
结束语
本文提出一类新的策略优化算法:PPO。它使用重要性采样方法,可以一次采样多轮训练。并且,PPO可以仅使用一阶优化算法就可以达到和trust region算法同样的稳定性和可靠性,最终整体性能表现也较优。
引用
[1] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.[2] Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. PMLR, 2016.

更多推荐